
关系型数据库进阶之Transaction manager
在前面的文章中,我们介绍了查询管理,查询优化以及数据管理,本文就来继续介绍Transaction manager相关的内容。它主要是用来保证每一个query都在它自己的transaction中执行。不过在此之前,我们需要理解一下ACID transaction。 ACID ACID...
东哥和系统设计开荒小分队的基地
在前面的文章中,我们介绍了查询管理,查询优化以及数据管理,本文就来继续介绍Transaction manager相关的内容。它主要是用来保证每一个query都在它自己的transaction中执行。不过在此之前,我们需要理解一下ACID transaction。 ACID ACID...
我们在前面已经介绍了客户端管理,查询管理,今天来介绍数据管理。 在这一步中,查询管理会执行相应的查询,这个时候就需要从表和index中得到数据了。它需要数据管理来获取数据,不过这里有两个问题: 关系型数据库使用的是transaction的模式,所以你不能够在任何时候都得到数据,因为同时可能有别人在使用或者修改数据。 数据的获取是数据库中所有操作最慢的操作,所以数据管理需要足够聪明,来把数据保存在内存buffer中。 本文我们就会来讨论关系型数据库是如何处理这两个问题的。...
在前面的文章中我们介绍了查询优化的基础,着重介绍的两个表的JOIN的优化。本文就来看看我们在实际中更常见到的多表JOIN的优化。 现在我们来假设有五个表进行join,我们需要从不同的表中得到一个人的不同信息,比如地址,mail,mobiles等等,简单的QUERY如下所示: 作为查询优化器需要找到最佳的查询数据的方法,这里有两个问题: 每一个join需要使用什么类型的JOIN?我们有三种可能的JOIN (Hash...
在前面几篇文章中,我们已经介绍了总体构架,客户端管理和查询管理。在查询管理中,有一个很重要的部分我们没有介绍,那就是查询优化,这也是本文所要介绍的内容。 所有的现代数据库都是基于cost进行优化的(Cost Based Optimization, CBO)。总体的思想就是看每一个操作的cost是多少,然后找出一个cost最小的路径来执行这些操作并获取结果。...
在前面几篇文章中,我们已经介绍了总体架构以及客户端管理,今天我们来继续介绍查询管理。 毫无疑问,查询管理是数据库的核心中的核心,也是最重要最难的地方。这个部分,哪怕是写的不好的query也会被转换成尽量快的方式来进行执行,在执行之后会把结果在返回给客户端管理。主要有一下几个步骤: 解析query,看是否有效 重写相应的query,去除一些没有必要的操作,主要是做预优化 优化相应的查询,主要是提高性能,转化成高效的执行计划和数据访问计划...
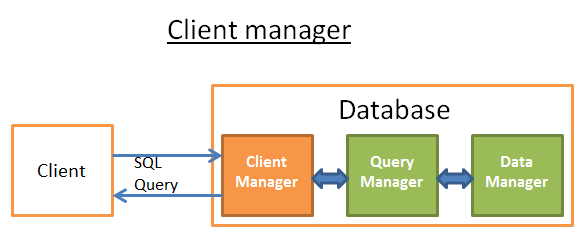
在上一篇文章中我们介绍了数据库的总体架构,今天我们将和大家来一起分析一下其核心组件中的重要组成部分:客户端管理。 客户端管理,顾名思义它是用来处理和客户端之间的信息交互的。客户端可以是一个web的server或者一个终端的用户/应用。客户端可以通过各种不同的方式来访问数据库,比如JDBC, ODBC, OLE-DB等等。 当连接数据库的时候,会执行下面这些步骤:...
一提到关系型数据库,我们可以看到它被在各个地方使用。有很多不同的关系型数据库,从最小的SQLite到复杂的Teradata。有很多文章在介绍如何使用数据库,但是很少有问题去深入地介绍它是如何工作的。假如你搜索“关系型数据库是如何工作的”这样的关键词,你会发现很少有问题进行深入详细的介绍。有时候,我们不禁会问,关系型数据库是不是太旧了,以至于都没有什么人来深入分析其中的内容? 作为一个开发者,我们需要有一点好奇心去深入看看我们每天使用的数据库内部是怎么样,假如你一直没有时间或者机会去深入了解其中的原理,那么本文将会是你的一个很好的选择。本文之所以称之为“进阶”是因为我们不会介绍如何去使用一些Query,而是假设你已经有了这些基础的知识,我们更注重其中的机理讲解。 一个数据库其实是信息的集合,而这个集合是可以很方便地访问和修改的。假如往简单的方面来想,那么它就是一系列的文件。事实上,最简单的数据库,比如SQLite其实就是一堆文件。当然SQLite又不是简简单单的一堆文件,因为它允许你: 使用transaction来保证数据的安全和连贯 能够很快的处理数据,哪怕是很大的百万量级的数据...
SVG是1990年代构思出来的,很长一段时间都不太受人待见,但现在则发展得越来越好,越来越多的人推荐和喜欢使用它。其实在2000年左右,对于SVG的支持还是很少的,直到2017年很多web浏览器都开始支持SVG,很多的向量程序已经支持导出SVG。当然毫无疑问,SVG已经越来越广泛地使用在WEB开发中。 我们来看看根源,其实SVG的流行并不是偶然。虽然一些传统的图片格式,比如JPG和PNG对photograph来说很完美,但是其实SVG对现在web开发中的扩展性,响应性,交互性,可编程性,性能以及可访问性这些要求来说,是一个近乎完美的选择。 什么是SVG?为什么要使用它? SVG是一个基于XML的矢量图形格式。XML使用的是HTML的tag,当然它更加严格而已。比如说,你不能省略结束标签,因为这会使得SVG的render出问题。 给你一个初步的感觉,下面就是一个SVG的代码,它就是画一个白色的圆,有一个黑色的边框...
首先,我要说的是把一个图片保存在MySQL中,再读出来是一个很不推荐的做法。我们只是看看假如真的要这样做,该如何做,最后我会和大家聊聊一般我们如何处理这种使用情况,以及不推荐这样做的原因。 首先图片是一个BLOB(Binary Large Object)是可以用来存储二进制的数据。这就是用来保存图片,文件等等的数据。因为这种object通常都很大,所以我们需要定义一个很大的域来保存信息。如何通过PHP来插入呢,其实很简单: 1)读取图片成二进制...
有时候,我们需要比较两个表的差异,希望能够返回两个表不同的行,那怎么才能有效快速地得到这个结果,本文就来做一个简单的介绍: 表格准备 我们来假设有下面两个表(PostgreSQL 语法): 使用UNION...
Follow:

More








Recent Comments