Database数据一致性介绍
数据一致性的场景很简单,假如我们把一个值赋给一个变量,那么我们之后立即再去读这个变量,突然发现它的值和我们想象的不一致,是不是很沮丧,对的,这就是数据的一致性。
x = 42 assert(x == 42) # throws exception
而在使用分布式的数据库的时候,尤其是那些对数据一致性不是很严格保证的情况下,这种情况经常会发生。也许你会问,什么?难道他们不应该给我们保证数据是一致的吗?我的回答呢,总得来说最后他都会能够保证的,但是这个中间的间隔时间则是取决于不同数据库的实现。
它们这样做是因为有一个trade off在里面,有些数据库为了提供可靠性和性能,则会牺牲掉一致性的保证。而有些数据库则允许你进行选择,你是要强一致性还是要高性能,比如Azure的cosmos DB和Cassandra。
数据库请求分析
我们来分析一下数据请求的时间线是什么样的,理想状况下,你的请求会被立即执行。

然而事实上肯定不是这样,我们需要时间连接存储数据的地方,然后还需要时间返回response给你。如下图所示:

这里最好的保证就是请求是在你调用和完成中间的某个时间点完成的。你可能会想,这个和你给变量赋值是类似,比如x=1,然后再读,你会发现它是1(前提就是这中间没有别的thread再写这个x)。但是假如是一个分布式系统,就不是这么简单了,你需要考虑别的server是如何更新到这个新的值的,这里就有一个设计的trade off,尤其是可靠性,性能和一致性之间的考虑。
假如我们有一个简单的分布式的键值存储,他由一系列的副本组成。这些副本在他们中间选择了一个leader,然后只要这个leader才能做写的操作。当这个leader接收到了一个写的请求,它会广播这个请求到所有的副本。即使这些所有的副本受到的请求是一样的顺序,他们更新的时间都是不同的。
所以,现在假如你来考虑读的情况,你该怎么处理?因为读是可以发生在leader上,也可能发生在任何一个副本上面,但假如所有的读都要到leader这边,那么显然性能就不会好。从另一个方面来说,假如我们让读发生在副本上,这样一来性能就会好很多,不管我们系统扩大到什么程度,性能显然都不会有大的问题。但是这里会有一个额外的问题,那就是因为每一个副本的更新可能都会不及时,所以他们的值就会有差别,这就会导致我们在不同副本读出来的值会有差异。
所以,最终这里有一个trade off,那就是系统的性能,可靠性和一致性。为了更好地理解这个关系,我们来先看看我们是怎么定义一致性的。
强一致性
假如所有的读写请求都是通过leader进行的,那么不管有多少的副本,对客户端来说,他们的操作都是原子的,他们总能够得到他们想要的数据。
当然因为一个请求并不是理解执行的,总归需要一个时间,数据的更新是发生在执行和完成之间,假如我们做这个保证,那这就是强一致性。

但是总是通过leader来执行也是有问题的,比如说假如客户端发送了一个请求给leader,在客户发送请求到leader之后,leader还是认为它自己是leader,但是事实上它已经不是了。这个时候,leader还来处理这个写的请求,那么系统其实就已经不是强一致性了。有处理这种情况,那么leader就需要问一下大多数副本,是不是还认为它是leader,只有这种情况下才能够执行写的请求,并且把response返回给客户端,这样的操作,显然增加了读的时间,性能必然会下降。
顺序一致性
前面我们讨论了强一致性,所有的读都会去leader那边,而事实上,这样做就会导致读的速度很慢,因为leader还需要和大多数副本进行商议。这种情况下为了提高读的性能,我们需要允许副本支持读。
尽管副本的读是在leader之后的,但是它的更新顺序始终是和leader一致的。假如客户端A总是读副本1,而客户端B总是读副本2,那么这两个客户端看到的数据就是不相同的,因为他们的副本并不是总是一致的。如下所示:
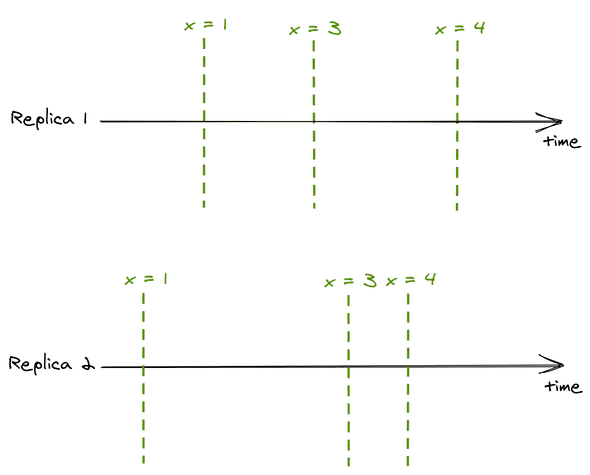
这里两个副本虽然更新的时间不同,但是他们的更新顺序则是相同的,这就是所谓的顺序一致性。
最终一致性
尽管我们希望增加读的速率,但是这里还有一个问题,副本假如出问题了怎么办?我们需要允许客户端查询所有的副本,从而来增加一致性。但是这里的对一致性来说就有了新的挑战,比如说假如客户端1开始是在副本1上查询,而副本2是落后副本1的,在某一个时间点,假如客户端切换到了副本2,会发现读出来的值竟然是以前的值,这个显然就是有问题的。这里唯一保证的就是所有的副本最终读出来的值都是一致的,这就是所谓的最终一致性。
使用最终一致性的系统是非常复杂的,因为这个和你平时的读写有很大的差别。可能会遇到很多很难发现的问题。所以这里就需要根据你的应用来看,它最终需要的是什么。比如说,这个最终一致性的系统对你想看看有多少人访问你的系统这样的应用是足够的,但对那些付费系统则显示强一致性是更好的选择。
总结
有很多文章会介绍各种一致性的模型,但是背后的理论其实是一致的:越严格的一致性,则需要牺牲越多的性能,以及发生问题时,可靠性越低。这就是所谓的PACELC理论。这个理论认为,分布式系统中有网络分区P,那么我们就需要在可靠性(A)以及一致性(C)之间进行选择。即使在没有分区的情况下正常运行,我们也必须在延迟(L)和一致性(C)之间进行选择。
参考文章:https://robertovitillo.com/what-every-developer-should-know-about-database-consistency/




Recent Comments