Category: Database


分布式系统之leader-followers Replication深入介绍
我们在前面有简单讲过Replication的作用,简单说就是为在多个机器上保存同样的拷贝来服务的。有了这个拷贝之后我们就可以做很多事情,比如说它可以成为一个读的源从而分散读的压力,它可以在原来数据机器出问题(或者deploy)等的时候作为一个backup等等。 这个想法其实很简单,但真正在我们做这个拷贝的时候,会遇到很多问题,比如说我们是使用同步还是使用异步来进行同步多个拷贝,如何保证多个拷贝之间的一致性等等。那么本文就来从各个方面详细介绍这些内容。 Leaders和Followers 我们把每一个保存数据的节点称之为replica,当我们有多个节点的时候,最明显的一个问题就是怎么去保证每个节点的内容都是一样的呢?其中最常见的方法就是基于leader的模式(也称为master-slave模式或者active/passive模式)。总得来说,它的工作方法如下: 一个节点是leader。所有的写操作都必须经过leader。...

深入浅出理解数据的序列化和反序列化
一般来说,数据的处理有两种类型。一种是在内存中,比如我们常见的结构体,list,数组等等。而另外一种就是把数据写到文件中或者在网络中进行传输,这个时候的数据传输说白了就是比特流,那么接受方如何解析这些接收到的比特流呢?这个时候就需要对数据进行序列化,把相应的数据转化成可以自解释比特流。然后接收方就可以通过反序列化的方法把这些比特流再转化成相应的结构体等等类型。 各种语言自带的格式 很多语言都有自带的序列化方法,比如Java.io.Serializable,Python的pickle等等。它们用起来很方便,但是也存在一定的局限性: 假如序列化是来自于特定的语言,那么反序列化也得是相应的语言。这就给不同语言之间的交流(比如客户端和服务端使用不同语言)带来了困难。 因为允许反序列化时实例化任意的类,所以很容易造成漏洞,给安全攻击带来了可能。...

数据库应用之数据分析
在早期数据库发明的时候主要是用来为实现商业功能的,比如说保存订单的信息,支付员工的工资等等。这类需求更多地是面向功能的,它的要求是相关的请求能够快速及时正确的执行,我们称这个流程为联机事务处理(OLTP, Online Transaction Processing)。 而随着数据库发展至今,一个更加常见的应用场景就是数据分析。比如说如何从淘宝订单中分析出商家每个月的销售情况,如何分析出哪些商品是爆款,如何得到某个新的功能给公司带来的点击量的增加等等。我们通常称这个流程为联机分析处理(OLAP,...
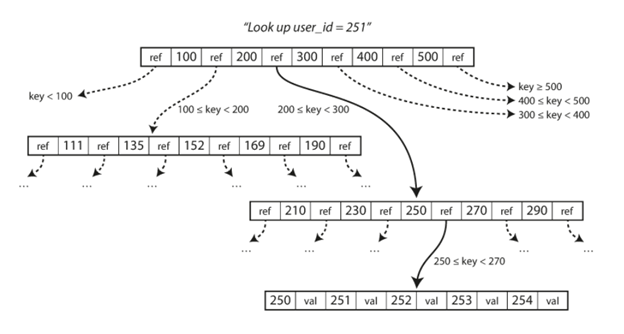
深入分析数据库中数据的存储和读取
我们日常的开发或多或少都会和数据库打交道,那么数据库中数据都是如何存储来保证读写的效率呢?本文就来详细地介绍数据库中数据的存储和读写。 最简单的数据库 我们首先来看一个最简单的通过bash来实现的数据库,它就是一个键值数据库,通过Bash函数来实现读写。 这里有两个函数,一个是写函数,就是简单的写入key和value对。另外一个函数是db_get()函数,它可以读出最新写入的一行数据。 我们可以这样使用它,这里我们就是写入了两个key,value,一个是123456,对应的后面的Json格式数据:'{“name”:”San...
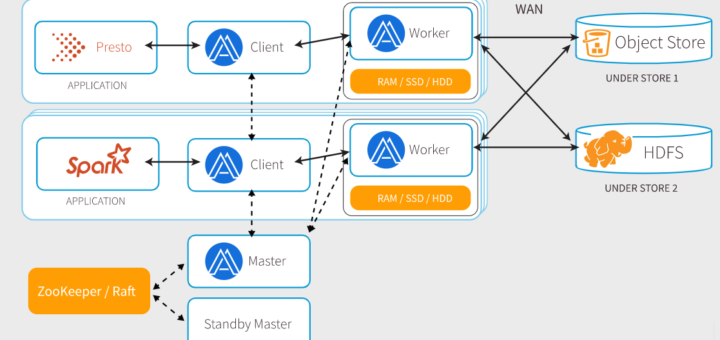
Facebook是如何加速SQL查询
在PB级别的数据上进行查询是一件事,如何在Facebook这种级别的产品上使用则是另外一件事。今年早期时候,他们把Alluxio分布式文件系统集成到了他们的数据架构上,实现了存储和计算的分离,以此用来加速查询。 Facebook很早就使用Apache hadoop,并且到现在还可以在Facebook的架构中看到他。它们已经把数据存储从Hadoop clusters中移开了,但是仍然使用HDFS在Warm Storage中访问数据,这是一个由Facebook开发的定制的分布式文件系统,用来在分离Hadoop之后进行数据存储的。...
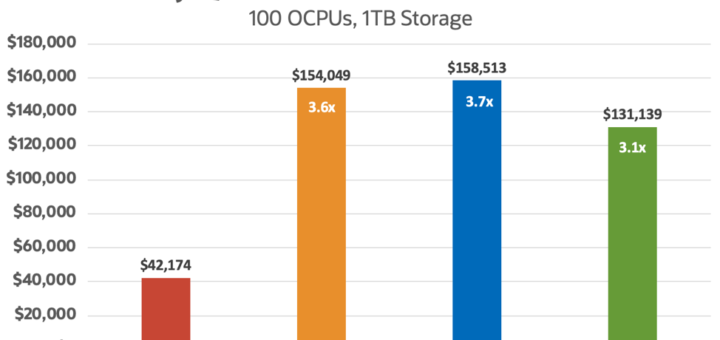
MySQL数据库服务介绍
MySQL团队现在把它引入到了Oracle Cloud架构上(OCI),这个服务是100%由MySQL服务开发,管理和支持的。 MySQL数据库服务和你所了解的MySQL几乎是一样的,只是说现在在云平台上支持了而已。它会自动执行很多耗时的任务,比如MySQL instance provisioning,补丁和升级,以及备份和恢复。用户可以很方便地扩展MySQL,检测云资源以及实现安全策略。用户的应用可以通过标准的MySQL...

关系型数据库进阶之Log Manager
我们在之前的文章中聊到,数据库为了提高它的性能,会把数据存在memory buffer中。但是这里有一个问题,就是假如一个已经committed的transaction crash掉了,你因为这个crash丢掉了memory中的数据,那就会出现了Durability的问题。当然你也可以把所有的数据都写到磁盘中,但是同样的问题,假如写到一半就crash了,这里就会发生原子性的问题。 所以这里我们的原则是任何通过transaction进行写的修改要么是全部完成要么就是什么都不做。 为了解决这个问题,有两个方法:...

关系型数据库进阶之Transaction manager
在前面的文章中,我们介绍了查询管理,查询优化以及数据管理,本文就来继续介绍Transaction manager相关的内容。它主要是用来保证每一个query都在它自己的transaction中执行。不过在此之前,我们需要理解一下ACID transaction。 ACID ACID...

Recent Comments