关系型数据库进阶之Transaction manager
在前面的文章中,我们介绍了查询管理,查询优化以及数据管理,本文就来继续介绍Transaction manager相关的内容。它主要是用来保证每一个query都在它自己的transaction中执行。不过在此之前,我们需要理解一下ACID transaction。
ACID
ACID transaction是一个工作单元,它主要包含4个方面:
- 原子性:transaction是“要么完成所有,要么什么也不做”,哪怕这个操作需要10个小时来执行。假如transaction crash,那么所有的state都需要roll back到之前的状态。
- 隔离性:假如有两个transactionA和B一起执行,不管A是在transactionB之前还是中间还是之后完成,结果都是一样。
- 耐用性:当transaction committed(成功完成),不管发生什么数据都会保存到数据库。
- 一致性:只有有效的数据才会写到数据库,一致性是和原子性以及隔离性相关。
在同一个transaction中,你可以运行多个SQL query来读,创建,更新和删除数据。但是当她们使用同样的数据的时候,就会造成混乱。我们来看下面这个例子:
- Transaction 1 从account A中取出100块钱,并存到account B中
- Transaction 2 从account A中取出50块钱,并存到account B中。
我们来从这个例子中看看ACID中各个属性:
原子性:不管发生什么,你都不能从account A中取出100块钱,而不存到account B中去。
隔离性:需要确保假如T1, T2同时发生,最终account A被取出150块并且account B收入150块。而不会发生别的,比如account B只收入50块之类的。
耐用性:需要保证T1在commit后,在数据库crash之前数据不会丢失。
一致性:需要确保没有钱被创建或者销毁。
并发控制
其实来保证隔离,连贯和原子性的最大问题就是如何处理同时有写操作:
- 假如所有的transaction操作都是读数据,那么他们显然可以同时进行。
- 假如有一个些操作和别的读操作同时发生,那么就需要有一个方法把这个修改隐藏起来,从而不影响别的读操作。同时,又需要保证写操作不会被别的操作去除了。
这个问题我们称之为并发控制。
最简单的解决方法就是顺序执行,也就是一个一个transaction进行执行,但是这样做有很多弊端,比如同一时间只能执行一个,没法使用多核,效率很低等等。
比较好的方法来解决这个问题,就是每次transaction创建的时候:
- 监测transaction中的所有操作
- 需要监测是否有多个transaction有冲突,比如读写同样的数据。
- 把有冲突的transaction之间进行重新排序,让他们的冲突部分变少
- 以一定的顺序来执行冲突的部分(不冲突的部分仍然可以同步执行)
- 考虑transaction取消的情形
锁管理
为了解决这个问题,大多数数据库都使用锁以及数据版本(data versioning)。其实这是一个很复杂的主题,我们这里主要讨论锁相关的内容。
悲观锁
这个锁背后的逻辑是:
假如transaction需要数据,它会先锁了相关数据,假如另外一个transaction也需要数据,它就需要等到第一个transaction释放数据。
假如使用互斥锁则cost就太大了,所以这就是为什么我们使用另外一种锁:共享锁:
假如一个transaction只需要读数据A,它会使用共享锁来锁住数据,并且读取数据。假如第二个transaction也只需要读取数据A,它也会使用共享锁来读取数据,假如第三个transaction也需要修改数据A,它需要获取互斥锁,但是它需要等到另外两个transaction也释放他们的共享锁。说白了,就是只读的可以使用共享锁,但是要修改,则需要使用互斥锁,它必须等待所有的读操作完成。

锁管理就是用来得到和释放锁的。它内部会把锁保存在一个hash表中,并且需要知道哪个transaction锁住了数据,以及哪些transaction正在等待数据。
死锁
不过使用锁会有一种情况发生,那就是两个transaction会永远一直在等待数据,也就是我们常说的死锁:

在上面这张图中,transaction A使用一个互斥锁在data1上,并且等待数据2。Transaction B有一个互斥锁在data2上,但是在等待data1。这样就形成了一个死锁。
- 当死锁发生的时候,锁管理就需要选择取消哪一个transaction来解决这个问题,但是这并不特别容易:
- 是否kill修改最少数据的那个transaction(主要是这样rollback的消耗比较小)?
- 是否kill等待时间比较短的transaction,毕竟另外一个用户等待的时间长了?
- 还是说kill掉执行时间短的transaction
- 假如rollback,多少transaction会被这个rollback影响?
不过不管怎么处理死锁,我们首先需要做的是如何判断是否有死锁。
hash表可以被认为是一个图,假如图中有一个圈,则意味着这里有死锁。但是因为检查圈其实是很复杂,一个简单的方法就是使用超时。假如一段时间没有得到锁,则会进入死锁状态。
当然在锁管理中,可以在创建锁之前判断一下是否会导致死锁。当然这种判断的cost也是很大的,所以这种判断通常也仅仅是一些基本的规则。
两相锁定
最简单的方法关于锁的处理,就是在transaction的开始的时候获取所有的锁,然后在transaction结束的时候释放锁。也就是说transaction需要在开始的时候的获得所有的锁,而这显然需要花费很多时间。
一个更快的方法就是两相锁定协议(DB2和SQL Server就使用这个),这个协议中一个transaction会分成两个象限:
- 在growing phase中,一个transaction可以获取锁,但是不能释放任何锁
- 在shrinking phase中,transaction可以释放锁,但是不能获取新的锁
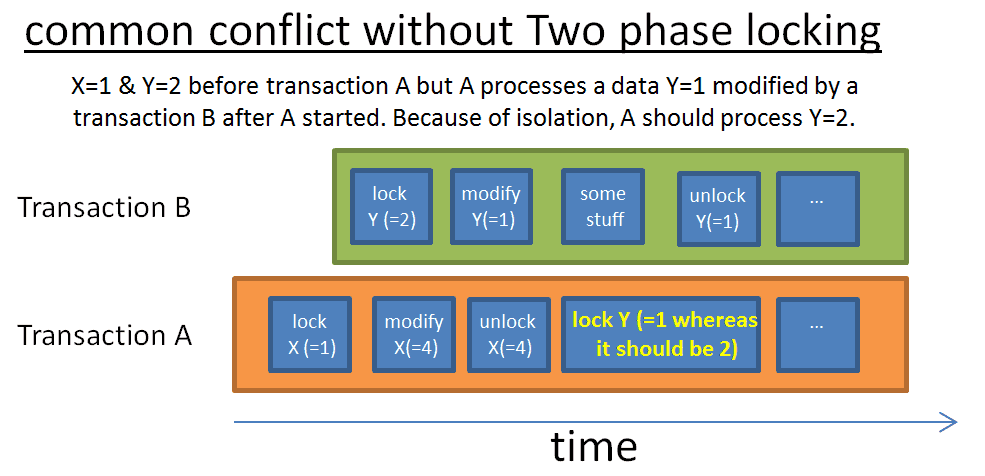
这两个简单的规则之下的想法是:
- 释放不再使用的锁,这样别的等待这个锁的transaction就可以及时得到相应的锁
- 获取的数据不能是在transaction开始之后修改的,否则就有数据一致性的问题。
这样一来,这个协议其实就很完美了,但是有一个问题,就是假如一个transaction修改了数据,但是在释放了锁之后它又cancel了(roll back)。所以,要解决这个问题,我们只需要保证:所有的互斥锁都必须在transaction的最后释放。
总结
当然真实的数据库其实比这种情况还要稍微复杂一点,它锁的力度也会有所不同,不过总得来说思想是类似的。




Recent Comments