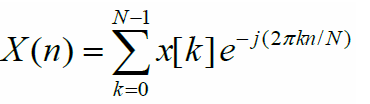
ShaZam深入分析之从数字声音到频率
我们在之前的文章中介绍了如何从模拟声音转变到数字声音。现在假如有了一个数字声音,你如何得到他的频率呢?这个部分很重要,因为ShaZam的算法基本都是基于频率的。 对模拟信号来说,这里有一个变化称为连续傅里叶变换。它可以把一个时间的函数转变成频率的函数。也就是假如把傅里叶变换应用到一个声音上,你就会得到它的频率。 但是这里有两个问题: 我们处理的数字信号,所以它是一个有限的不连续声音。 为了更好地理解音乐内部的频率,我们需要把傅里叶变换应用到整个音乐信号的更好的部分,比如我们需要把它应用到0.1s的部分。...



Recent Comments