
LinkedIn直播系统是如何实现每秒百万点赞的
现如今直播领域非常火爆,而一个大V的直播很容易就会吸引上百万的用户同时在线。LinkedIn的直播领域专家Akhilesh Gupta在QCon London 2020上介绍了LinkedIn是如何实现百万点赞的架构,本文就根据Akhilesh在会议上的介绍总结了相关的实现方法供大家参考。 场景分析...
东哥和系统设计开荒小分队的基地
现如今直播领域非常火爆,而一个大V的直播很容易就会吸引上百万的用户同时在线。LinkedIn的直播领域专家Akhilesh Gupta在QCon London 2020上介绍了LinkedIn是如何实现百万点赞的架构,本文就根据Akhilesh在会议上的介绍总结了相关的实现方法供大家参考。 场景分析...
熟悉我的人都知道,我们每周都会举办一次分布式系统话题的讨论(对活动感兴趣的同学可以参考这个网址:https://donggeitnote.com/2021/07/24/topic-introduction/,当然这个不是我们今天讨论的重点),这个讨论的活动安排会发布到各个微信群,这样感兴趣的同学就可以来参加了。在上周五因为我个人的失误,没有更新活动通知中的时间,于是就导致这个活动的消息需要重新发布,这其实给帮忙发布活动的同学带来了很大的困扰。虽然最后也解决了问题,但是过程并不是很开心。所以我就想应该写个小程序来通知一下,这样一方面可以解决我们遇到的问题,比如哪次的时间再写错了,我们只要更新一下小程序内的内容就可以了。另外一方面也可以让一些主动想了解讨论话题的同学能够有一个统一的地方来发现话题。说做就做,一到周六我就开始来着手搞这件事情了。 需求分析 需求大概是我们第一步需要了解清楚的东西,在真正着手之前,我把最基本的需求简单列了一下,如下所示: 活动管理页面 这个页面是让活动发布者管理已经创建的活动以及发布新的活动,主要的功能包括以下几个方面:...
今天中午在家吃午饭的时候,孩子妈妈说早上和中午用的筷子比较多,待会吃完可能需要先洗一波筷子,不能直接放到洗碗机里面(我们家基本都是一天开一次洗碗机),否则晚上吃饭筷子就不够了。我最近沉迷于系统设计,于是就和我们家的七岁小朋友聊起了该如何解决这个问题。 需求 功能需求 从妈妈的描述中,我和儿子总结了以下几个功能需求: 家人可以用筷子进行吃饭。...
我们在分析各种分布式系统场景时不可避免地会讨论到数据的读写,很多时候我们会对数据的读写做很多的优化和特殊处理,而这些操作的背后根源都离不开数据存储的硬件,本文就来和大家谈一谈这其中设计的各种硬件和相应的技术。 Cache和读写 我们都知道把数据放到内存中,这样有读请求过来的时候就可以直接从内存中读取到相关数据(hit cache的情况),而不需要去访问具体的物理磁盘,从而减少了disk I/O的操作。同样地,写也可以写到内存中,只是和读不同的是,内存写终究只是一个中间状态,你最终还是要写到磁盘中才行,所以内存到写操作来说只起到一个delay的作用(当然假如你没有persist保存的情况下,可能也不需要写到磁盘,但我们讨论正常的需要persist保存的情况)。...
我们在研究分布式文件系统的实现时,不可避免要讨论MapReduce技术。比较常见的使用这一技术的有HDFS (Hadoop Distributed File System),它是Google文件系统GFS的开源实现。当然很多别的分布式文件系统,比如GlusterFS,QFS(Quantcast...
我们现实工作中很多时候想知道当前服务器的各项性能指标,比如说CPU的使用率是多少,还有多少内存,各个磁盘的IO是什么样的情况等等。假如我们使用的是windows操作系统,那么它其实已经内置了一个很强的性能监控系统,本文就来介绍一下我们如何使用这个性能监控系统。 Windows Performance counter系统介绍 总得来说Windows...
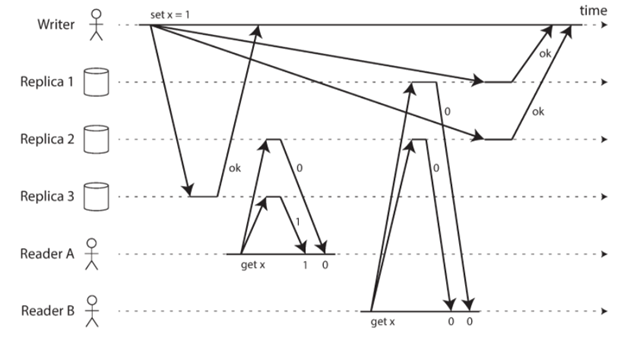
我们在前面《分布式系统中的Linearizability一致性的概念介绍》介绍了Linearizability的基本概念,本文就来详细介绍一下我们如何来实现Linearizability。 我们再来简单回忆一下Linearizability的介绍,他其实就是说所有的replica都像只有一个一样,那么我们是否有个暴力解,就是真的只有一个拷贝,没有replica,这样不就是Linearizable的了?你是对的,哈哈,不过这个显然不是我们想要的答案,毕竟这样一来,如果这个节点出了任何问题,你整个读写就都不能继续了。 那么我们先来看看各种分布式的模型,看看他们能不能Linearizability: 单leader的replication 在单leader的系统中,假如读都是从leader来的话,或者你使用同步更新replica,那是有可能实现Linearizability的,但是注意也只是有可能,毕竟有可能leader出问题,比如leader自己还认为自己是leader,但事实上已经不是了,这种情况就有可能不是linearizability了。...
分布式系统中一致性一直是一个大家热衷讨论的话题,这里的一致性是指假如你同时到两个节点读取数据,你很可能看到的是不同的数据。毕竟发生在一个节点上的写操作同步到另外一个节点总是需要时间的。 我们最常见的说法就是“最终一致性”,也就是说假如没有写操作,所有的节点在一段时间之后就会一致了。目前大多数的数据库都是支持这种一致性的,但是这个一致性非常弱。你仔细想想它其实什么都没有保证,比如你写了一个数,你再去读,读到什么值根本就没有任何保证,只是说你最终能读到一致的值,这个最终是多长时间之后谁也不知道。所以说这样的“最终一致性”其实给应用开发带来了很多困难,也有可能导致很多Bug。 那么有没有什么更强的一致性保证呢?答案是当然有,但是需要注意的是一致性越强,它的性能或者错误容忍度就会越差,毕竟十全十美总是很难。本文就来介绍一种强一致性技术:Linearizability。 概述 我们上面提到在一个“最终一致性”的系统中,你同时访问不同的数据replica,得到的值可能是不同的。那么能否有一种机制保证我们任何时候访问同一个数据replica得到的值一直都是相同的呢?这种保证的就是Linearizability背后的思想:任何时候整个系统就像只有一个拷贝一样,不管你访问哪一个replica,得到的结果都是一样的。...
我们知道分布式系统中各个服务器都是通过网路进行连接的,这样导致的结果就是你很难知道各个服务器的真实状况,比如你判断另外一台服务器是否有问题的唯一办法就是发送一个请求给他,只有收到了回应,你就认为它是好的,假如没有收到回应,你就很难判断对面的服务器是否有问题,因为这个没有回应很可能是发生了网络故障,也可能是对端机器真的出问题了。因此,在分布式系统中我们如何来准确判断这些问题呢?本文就来详细介绍相关的方法。 基于多数的(Majority)事实 很多时候我们一个节点可能不是真的有问题,比如说它正在进行GC,那么在GC的这段时间内它就不能回应任何请求,这个时候从节点本身的来看,它自己是很ok的,没有任何问题。然而从别的节点来看,这个GC的节点就和出问题的节点一模一样,发请求它不回,重试也没有反应。所以别的节点就会认为它是有问题的。从这个角度来看,节点本身其实也是很难知道自己是否问题的。 现在比较流行判断节点是否有问题的算法都是基于多数的决策,比如说我有5个节点,那么大家一起来投票,假如有超过一定数量的节点(一般来说超过半数,这里就是有三个节点)认为它有问题,那么我们就认为这个节点是真的有问题。哪怕这个节点本身是没有问题的,但是只要有多数认为有问题,我们就认为它有问题。这里使用多数来决定是因为多数就意味着不会有冲突,因为一个系统中不可能存在两个多数,只可能有一个。 Leader和Lock...
时钟是一个我们常常会使用的东西,比如我们会用它来确定一个事情发生的时间或者说一个请求花费的时间。然而在分布式系统中,每个机器都有他们自己的时钟,通常来说是由它们本身的硬件来决定的(比如晶振等),它们都不是精确准确的,所以每个机器之间的时钟都或多或少有点差别。所以当我们需要使用不同机器的时钟时,比如比较两个发生在不同机器上事情发生的先后顺序的时候,就很难说哪一个事情是真正先发生哪一个是后发生的。本文就来介绍一下一般如何处理这个问题。 单调时钟(Monotonic)和当天的时间(Time-of-Day Clock) 在现代计算机上,一般有两种时钟,一个是单调时钟另外一个是当天时间。虽然两者都是时钟,但它们其实有很大的差别。 当天时间...
Follow:

More








Recent Comments