LinkedIn直播系统是如何实现每秒百万点赞的
现如今直播领域非常火爆,而一个大V的直播很容易就会吸引上百万的用户同时在线。LinkedIn的直播领域专家Akhilesh Gupta在QCon London 2020上介绍了LinkedIn是如何实现百万点赞的架构,本文就根据Akhilesh在会议上的介绍总结了相关的实现方法供大家参考。
场景分析
这个问题的使用场景很简单,就是我们有一个直播视频,然后有很多不同的用户在同时观看,每个用户都可以对视频进行点赞,系统需要把这个点赞的信息发送到每个正在观看视频的用户端,然后在他们对应的UI上显示点赞的图标。这里最大的挑战就是假如有大量的用户在同时观看并点赞,如何及时有效地把相关点赞的信息发送到观看的用户端。
服务端如何把点赞信息发送到客户端
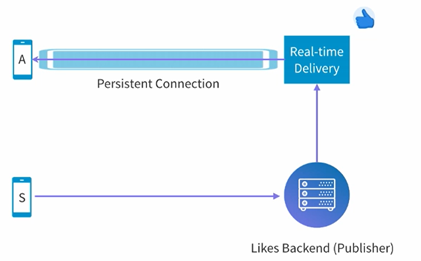
我们从最简单的架构开始,用户S点了一个赞,发送了一个HTTP的request到了后端,一方面这个点赞的消息会被保存到后端数据库,另一方面我们需要有一个方法来把这个点赞的消息发送到别的用户端(用户A)。Linked采用的方法很简单,就是在用户A打开视频的时候,和服务端建立一个HTTP长poll链接,这个链接不会disconnect,所以当server端有需要发送的信息(比如点赞消息),它就会直接通过这个链接发送到用户端。用户端只要根据server的URL来创建一个EventSource的object,然后根据收到的内容来独立处理就可以了。
简单架构如下所示,S发送点赞的信息到后端,后端会把这个信息publish出去,然后实时的delivery的系统会把相应的信息发送到已经建立长链接的client端。
用户端收到的信息可能就是如下所示,它然后就可以解析进行处理了。

服务端链接管理
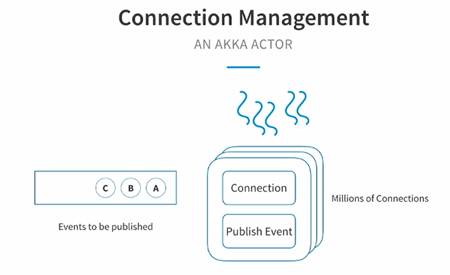
有了上面简单的架构之后,我们知道信息的传递主要是靠这个长链接,那么当有很多用户的时候,server端如何来管理这些链接呢?LinkedIn使用的Akka来进行管理的,Akka是一个高性能高容错的分布式并行框架。它有实现一个很经典的Actor模型,Akka Actor拥有自己的状态和行为,行为会定义说我收到某一个信息之后如何修改状态,每个Actor都有一个mailbox,所有其它Actor发送过来的消息都会进入该邮箱。Actor很轻量,所以很容易就能够支持到百万级别的Actor(1G内存可支持约300万个Actor)。
这样一来在LinkedIn的直播系统中,每个Actor的状态就是一个connection,行为就是一个publish event,它可以定义我们如何把event publish到长链接的另外一端(用户端)
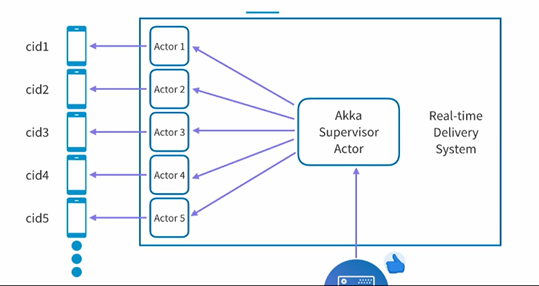
这样一来一个server就可以管理很多connection,当有一个点赞的信息到来的时候,就会发送到一个supervisor actor,然后它会把这个信息分发到不同的actor中,这些actor其实每一个就对应一个和用户端的链接,从而把相应的点赞信息发送给用户端。
不同用户端的区分
上面的架构还是不错的,但是现实肯定不会这么简单,我们上面的架构中有一个点赞的信息就直接发送给了所有的用户端,事实上我们不同的用户可能在同时观看不同的直播,显然我们不应该把不同的直播点赞混淆,因此我们就需要一个机制来区分不同的直播。
方法也很简单,就是当用户端建立连接的时候,告诉一下server你正在看的直播内容,这样有了一个mapping的关系,在我们发送点赞信息的时候就可以根据这个mapping的值找到应该发送的用户端,如下图所示:
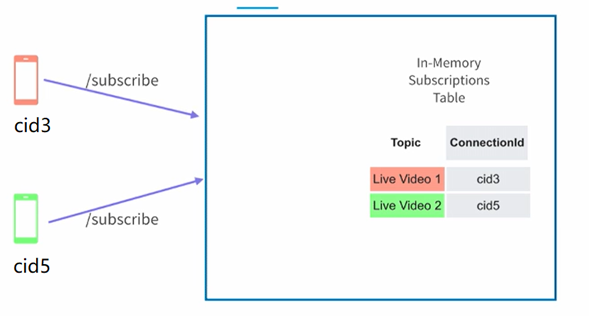
这里当cid3看红色直播的时候会做一个subscribe,然后在server端把这个信息保存到一个mapping的表中,它会记录cid3在看红色直播。同样的也会记录绿色直播是cid5在看。这样一来随着时间的推移系统就会如下所示,当有一个点赞的消息过来了,我们假设是一个绿色直播的点赞,在supervisor这边就可以查询mapping的表格,从而知道需要把这个点赞的内容发送到cid1,cid2和cid5。这样就解决了不同用户端的区分问题。
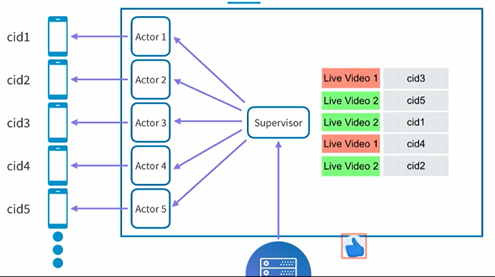
在结束这一段之前,一个有趣的问题就是我们这个mapping的表是否需要persisted,还是说放在in-memory中就可以了,答案是in-memory就可以了,为什么呢?persisted的一个重要的目的就是说当server crash的时候我们还能够恢复,而这里假如我们的server crash了,其实它和用户端端的连接也就断了,你即使恢复了这个mapping的表也没有用,也还是没法发送消息给相应的用户端。这也就是为什么我们使用in-memory的mapping的原因。
多客户端的处理
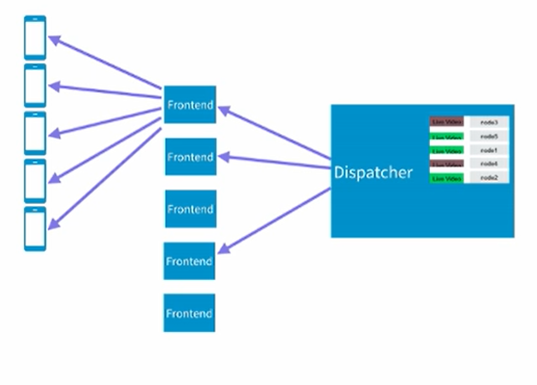
有了上面的架构之后,基本的功能就实现了,但是问题也很明显,假如这个时候我们有很多的客户端,比如说一万个用户或者几十几百万个用户同时连接server,显然单个server是没有办法handle这么多链接的。这个时候怎么进行处理呢?思想其实很简单,就是使用更多的server来支持更多的客户端连接,我们这里先把这个server称之为frontend的server。我们把原本的dispatch放到另外的server中,这样整个架构就分成了下面这样的层级架构:
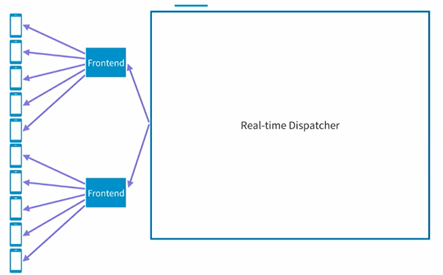
每个Frontend的server服务于一定数量的客户端,然后dispatcher只要负责向frontend发送相关的消息(点赞信息)即可,在frontend收到对应的消息之后,它会根据in-memory的mapping table来决定需要把消息发送给哪一个客户端,从而完成最终的消息传递。这个架构可以很好的服务几百万级别的用户端。
现在还有一个问题需要解决,就是dispatcher是如何知道该把消息发送给哪个frontend,而不是说所有的frontend都发送呢?这个问题的解决方法和上面的不同用户端是类似的,假如我们能够让frontend也向dispatcher subscribe一下它感兴趣的直播视频,那么我们就可以只把相关的消息发送给他就可以了。所以需要在dispatcher端维护一个类似的mapping表,只是这次值不是client端id而是frontend的id而已。
如下所示,和之前的client端到frontend的subscribe类似,在dispatcher中也维护了一个表格。
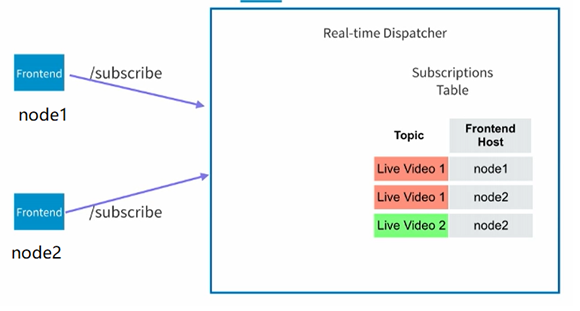
所以当点赞的消息到了dispatcher之后,它就可以把这个消息根据mapping表格的内容发送到对应的frontend端,如下所示:
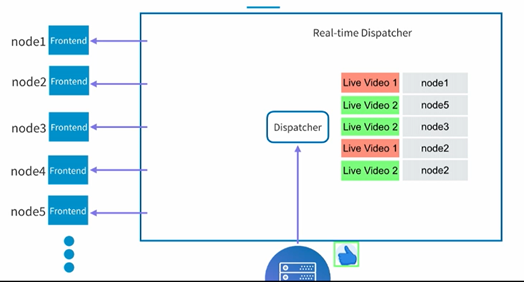
然后各个frontend再根据in-memory的table把消息发送最终的客户端。
多点赞的处理
这个时候我们解决了很多客户端的问题,但是假如我们同时有很多人在点赞,比如每秒有一万个人来点赞,上面提到的架构还需要改进吗?很显然,这个时候一个dispatcher可能会撑不住,解决的方法也很简单,就是增加dispatcher的机器,这样我们的架构就可以变成下面这样了:

多个dispatcher可以分别处理不同的点赞消息从而达到scale的目的。
这个时候我们再回头来看看我们dispatcher中的mapping的表格是否需要persist还是说也像frontend那样放到in-memory中就可以了。这里显然还是存到一个key value的表中会比较好。原因也很简单,假如这里一个dispatcher出问题了,我们仍然希望别的dispatcher能够take它的职责,而不是就忽略它所对应的那些frontend server(和frontend那边不同的是,这里不是长连接,所以完全可以用不同的dispatcher来处理和frontend之间的通信)。这样一来整个架构就变成了下面这样。
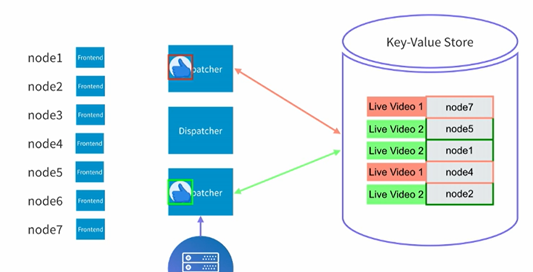
所以这个时候整个流程就变成了,点赞信息发送到某个dispatcher,然后dispatcher会到key-value store去看哪些frontend对这个直播感兴趣,从而把相关的点赞信息发送到相关的frontend,frontend收到对应信息之后,再根据它的in-memory的表格决定最终发送到哪一个用户端。从而完成这个发送的流程。
多数据中心
目前来看整个架构运行得都很好,然后LinkedIn发现了一个新的问题,就是如何进行跨数据中心的处理,也就是说假如一个点赞的消息发生在一个数据中心,如何把这个消息dispatch到不同的数据中心,如下所示:
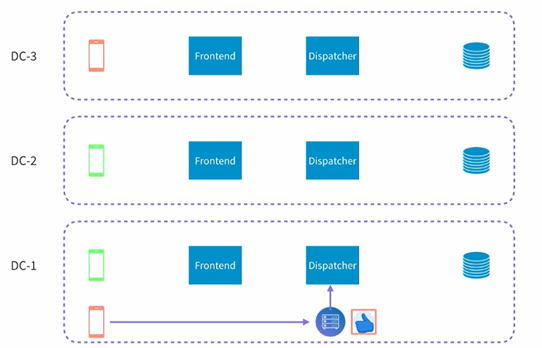
假设有三个数据中,然后在DC1有人对红色直播进行了点赞,我们如何把这个点赞消息发送的别的数据中心。这里其实有两种处理的方法:
- 第一种就是subscribe的时候跨数据中心,这样每个数据中心的key-value store中都有别的数据中心的frontend的信息。
- 第二种就是subscribe还是单数据中心,但是dispatcher则进行跨数据中心的分发,然后让每个数据中心自己根据它本身的key-value store来决定是否需要进行分发。
LinkedIn选用了第二种方法来进行处理,如下图所示:
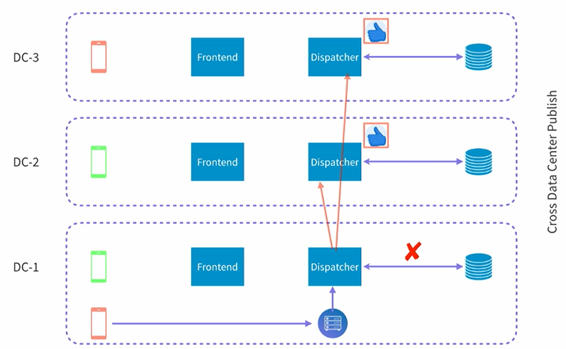
当第一个dispatcher收到信息的时候,它会把这个消息分发给所有的不同的数据中的dispatcher,然后各个dispatcher就可以按照之前的做法来做了。
性能数据
在有了上面的架构之后,我们来看看这样的架构可以支撑什么样QPS的场景,或者准确地说这样一套架构支撑一个1000万的同时在线的用户,并且每秒有5万用户点赞需要多少台机器。
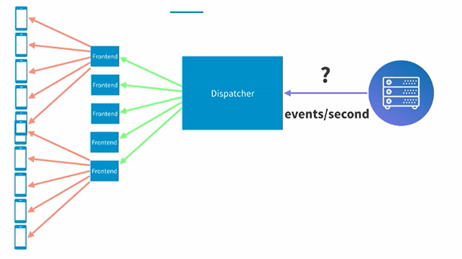
首先我们看第一个部分,就是每个frontend的server来同时支持多少客户端,LinkedIn测试的结果是可以支持>100,000客户端。也就是假如同时有1000万用户同时在线,需要100台frontend的机器就可以了。
下面我们来看第二个部分,也就是一个dispatcher每秒能接收多少events,这个会决定我们假如我们有很多人同时点赞,需要多少dispatcher的机器才能够撑住,LinkedIn测试的结果是5K,也就是说假如每秒有5万用户点赞,我们只需要10台dispatcher的机器就可以撑住了。
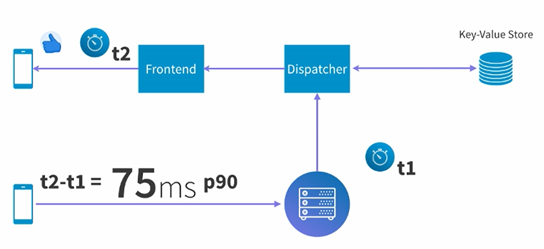
最后我们来看看这个系统中,点赞到最终发送到用户端的延时是怎样的呢?这里测试的数据时间点t1是后端向dispatcher发送点赞的时间点,t2是frontend开始向客户端发送的时间点。这两个时间点之间的延时P90是75ms,还是很快的,当然另外两端和客户端的交互就收到很多不确定的因素影响了,不计入考虑也是可以理解的。
总结
至此我们就把LinkedIn的这套点赞系统总结完毕了,它其实也可以应用任何直播中的数据交互系统,比如留言等等。大家感兴趣也可以参考原会议的视频: https://www.infoq.com/presentations/linkedin-play-akka-distributed-systems/。




Recent Comments