关系型数据库进阶之数据管理

我们在前面已经介绍了客户端管理,查询管理,今天来介绍数据管理。
在这一步中,查询管理会执行相应的查询,这个时候就需要从表和index中得到数据了。它需要数据管理来获取数据,不过这里有两个问题:
- 关系型数据库使用的是transaction的模式,所以你不能够在任何时候都得到数据,因为同时可能有别人在使用或者修改数据。
- 数据的获取是数据库中所有操作最慢的操作,所以数据管理需要足够聪明,来把数据保存在内存buffer中。
本文我们就会来讨论关系型数据库是如何处理这两个问题的。
Cache管理
就像我们前面几篇文章提到的一样,数据库的瓶颈就在于磁盘I/O,所以为了改进性能,需要使用cache管理器。
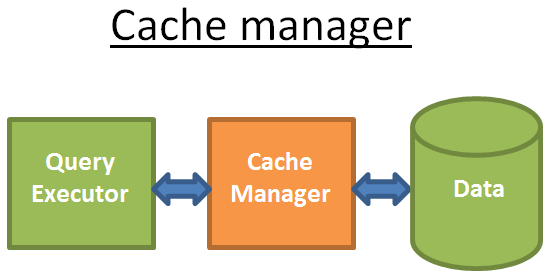
Query的执行器并不是从文件系统直接获取数据,而是通过cache manager来请求数据。Cache manager有一个memory的cache,我们称之为buffer pool。显然动态地从cache请求数据会增加数据获取的速度。一般来说memory相比磁盘来说会快100到100K倍,当然这还取决于决定的硬件和读写方式。
但是这里就会有另外一个问题,就是cache manager需要在query执行之前就获取到相应的数据,否则就还需要访问磁盘来数据。
预获取
query执行器其实是知道它所需要的数据,因为它知道整个query的所有流程。基于此,我们可以让query执行器处理第一部分数据的时候,就要去cache manager去预加载第二部分的数据,然后当它处理第二部分的数据的时候,就让cache manager去预加载第三部分的数据,这样循环下去。
Cache manager会把所有的数据保存在它的buffer pool中,为了检查相关数据是否还需要,cache manager在所有的cache数据中加入了一个额外的信息(我们称之为latch)。
当然有时候query执行器也不知道它下面要什么数据,这个时候就会使用一些特殊的预加载(比如,query执行器要数据1,3,5,那么它很有可能在未来需要数据7,9,11)或者顺序获取(这种情况下,cache manager就继续加载磁盘中后面的数据)。
为了探测预获取的效率,数据库提供一个称之为buffer/cache hit ratio的指标,这个指标会显示当请求一个数据的时候,有多少次是可以直接在cache中获取而不需要访问磁盘。
但是另外一个问题就是memory的大小毕竟有效,所以假如要加载新的数据,那么就得去除一些旧的数据,而这些加载和去除都是需要磁盘以及网络I/O消耗的。假如有一个查询经常执行,那么我们就会频繁地加载和去除相关的数据,这显然是不太合理的,那该如何处理呢?现代的数据库使用一种称之为buffer替换的策略。
buffer替换策略
现代的数据库(至少SQL Server, MySQL, Oracle和DB2)基本都使用LRU算法。
LRU就是Least Recently Used。这个算法的思想就是把最近使用的数据保存在cache中,因为它很有可能会再次被使用。
下面就是一个例子:

这个例子中,buffer能够保存三个元素:
- Cache manager使用数据1,然后把它放到空buffer中。
- Cache manager使用数据4并且把数据放到半缓冲区
- Cache manager使用数据3,并且放到buffer中。
- CM 使用数据9,这时候会把数据1从buffer中remove,因为它是我们最早使用过的。
- CM再次使用了数据4,4已经在buffer中了,那么它就会被设为最新使用过的数据。
- CM使用数据1,这个时候buffer已经满了,所以会把最旧的数据9移除掉。
这个算法看起来不错,但是也有一些问题,比如假如需要对一个很大的表进行全扫描怎么办?也就是说假如表/index的大小比cache的buffer大小还大怎么办,因为这个时候整个buffer都会被remove掉。
改进
为了解决这个问题,有些数据库就做了一些改进,比如Oracle文档就说:“对很大的表,数据库会使用一个路径进行读取,只会加载一个block,从而防止把buffer cache爆了。对于中等大小的表,数据库可能使用上面这种block的读或者cache读。假如决定使用cache读,那么只替换LRU链表中最后的一个block,而不会把这个cache buffer清空”。
还有一些别的优化,比如使用LRU-K,SQL Server就是使用的LRU-K其中K=2。
LRU-K的基本思想如下:
- 它考虑最后K次使用的数据
- 使用数据被使用的次数来做一个权重
- 假如有新的数据被加载到cache中,一些旧的数据但是被经常使用的数据不会被清除(主要是根据权重来判断)
- 这个算法不会把旧数据保存在cache中,假如这个数据没有被使用
- 因此这个权重会随着时间减少(假如不在被使用的话)
计算权重的cost其实还是蛮大的,这也是为什么SQL Server只使用K=2,这个值算是一个折中的选择。
别的算法
当然还有一些别的算法来处理这个问题:
- 2Q (和LRU-K比较类似的算法)
- CLOCK(同样和LRU-K类似)
- MRU(最近使用)
- LRFU(最近最少使用)
- …
写buffer
上面我们讨论的都是读数据时候的处理,其实在写数据的时候也是有一个buffer的,这个buffer可以用来存储数据并把他们通过bunch来flush到磁盘,而不是一个一个地写数据。
需要注意的是buffer存储的page(数据的最小单元)而不是我们通常感觉的一行数据。一个page是一个buffer pool,它会被设为dirty当被修改并且没有写到磁盘的时候。有很多算法会来决定何时把dirty page写到磁盘中,这些算法和我们后面要讲的Transaction有很大的关系,所以我们后面讲transaction的时候再来讨论。


Recent Comments