关系型数据库进阶之查询优化二
在前面的文章中我们介绍了查询优化的基础,着重介绍的两个表的JOIN的优化。本文就来看看我们在实际中更常见到的多表JOIN的优化。
现在我们来假设有五个表进行join,我们需要从不同的表中得到一个人的不同信息,比如地址,mail,mobiles等等,简单的QUERY如下所示:
SELECT * from PERSON, MOBILES, MAILS,ADRESSES, BANK_ACCOUNTS WHERE PERSON.PERSON_ID = MOBILES.PERSON_ID AND PERSON.PERSON_ID = MAILS.PERSON_ID AND PERSON.PERSON_ID = ADRESSES.PERSON_ID AND PERSON.PERSON_ID = BANK_ACCOUNTS.PERSON_ID
作为查询优化器需要找到最佳的查询数据的方法,这里有两个问题:
- 每一个join需要使用什么类型的JOIN?我们有三种可能的JOIN (Hash Join,merge
Join, Nested Join)
- 先做哪个JOIN再做哪个JOIN?
下面这个是一个简单的示意图,有四个表,三个JOIN的情况,显然五个表的情况会更加复杂。
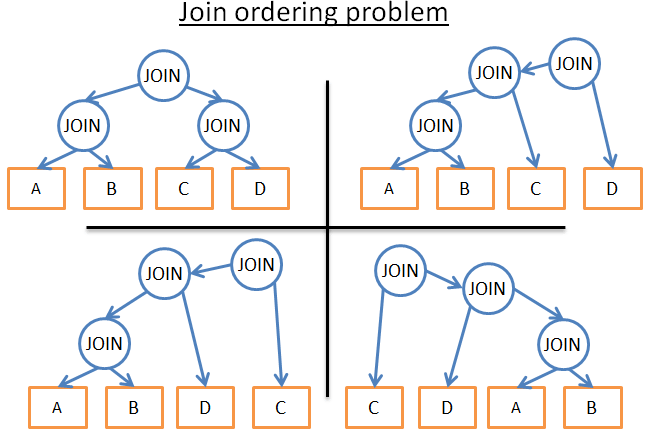
好的,那我们该怎么做呢?
1)暴力解法
遍历所有的可能性,然后找到最佳的方法。在上面的例子中,每一种join有三个可能(HASH, MERGE, NESTED),对于给定顺序的JOIN就有3^4中可能,而JOIN的顺序也是不定的,四个JOIN其实有(2*4)!/(4+1)!种可能的排序,这样一来,这个五个表的JOIN有 3^4*(2*4)!/(4+1)!种可能。
也就意味着,有27216中可能的计划。假如说merge join有0,1,2 B+ tree index,那么这种可能性就变成210000种了。而这还只是一个简单的JOIN。
2)只试验一些计划,然后选择其中最好的
因为可能性太多了,那么我们随机选择其中一些,然后计算他们的cost,选择其中最好的。
3)应用一些规则,来减少可能的计划
这里通常有两种规则:
- 使用一些简单的逻辑规则去除一些没有用的可能性,只是说这种去除不是很多。比如“nested loop join的inner relation必须是最小的数据集“
- 使用一些有侵略性的规则来减少可能性。比如“假如一个relation很小,那么使用nested loop而不使用merge join和hash join”
动态编程,贪婪算法以及启发式编程
真实的数据库可能会使用上面我提到的方法中的多种,总得思想就是在有限的时间内找到最佳的方法。
大多数时候,优化器其实找到的不是最佳的,而是一个相对最好的。
对于小的查询,我们可以做一个暴力解法找到最好的方法,甚至一个中等的查询,都是可以排除一些没必要的计算做到暴力查找的。这种方法我们称之为动态编程:
动态编程
这个思想就是很多执行计划是类似的,比如你看下面两个计划:
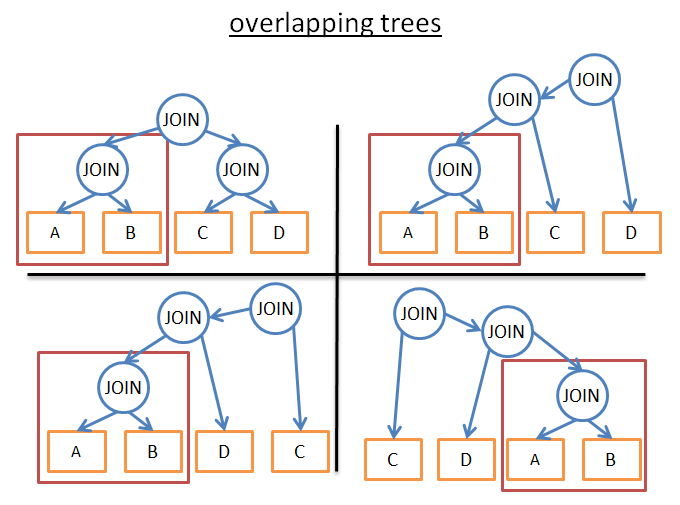
你可以看到A JOIN B这个子树其实是一样的,所以我们没有必要每次都计算它,可以计算一次并保存下来,这样下次再遇到就可以直接使用了。
用了这种方法之后,你会发现时间的复杂度直接变成了3^N。在我们上面的例子中,我们有4个JOIN,也就意味着我们把它从336改成了81。假如我们有8个JOIN,则能通过这个方法从57657600优化到6561。
那对于大的查询,还能使用动态编程吗,答案是也是可以的,我们可以使用一个额外的规则来去除一些可能性。
- 假如我们分析一些特殊类型的计划(比如 左深度树),我们就只要n*2^n而不需要3^n.
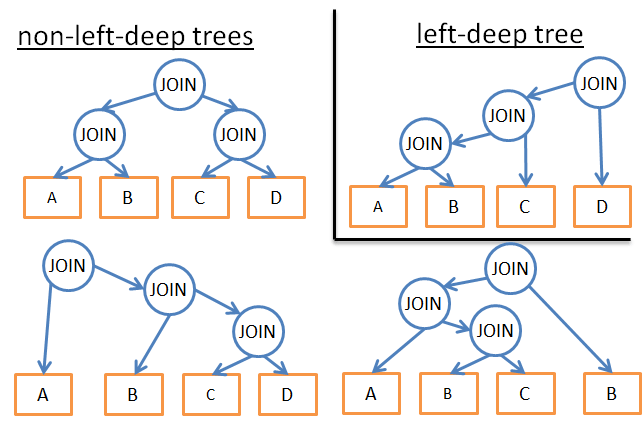
- 假如我们可以加入一些逻辑规则来避免一些pattern的计划(比如,“假如表的index在预测中,就不要在表上使用merge join,而是只在index做”)这就会减少很多可能性。
- 在flow中加入规则(在执行其它所有操作前执行join操作)也会减少可能性。
贪婪算法
但是对一些特别大的查询,另外一种算法则会被使用。
它的思想就是根据一些规则来递增地创建查询计划。根据这个规则,贪婪算法每次都发现一个最好的方案。这个算法用一个JOIN来开始查询算法,然后每次都增加一个新的JOIN,并使用同样的规则。
我们来举个例子,我们使用四个JOIN来join五个表(A,B,C,D,E)。首先,简单来说,我们选择nested join作为可能的join。然后我们使用的规则是“使用最低cost的join”:
- 随意选择5个表中的一个(我们假设选择A)
- 计算和A进行JOIN每次的cost
- 找到A JOIN B的最低cost方案
- 然后计算别的表和A JOIN B结果的cost
- 找到最佳的结果,比如说 (A JOIN B) JOIN C
- 然后计算别的表和 (A JOIN B) JOIN C结果的最佳方案
- ..
- 最后,我们发现 (((A JOIN B) JOIN C) JOIN E) JOIN D可能是最佳的方案。
这里我们开始是任意地选择了A开始的,下面我们用同样的算法来计算从B开始,从C开始,从D 开始以及从E 开始,然后选择最低cost的方案。
其实,这个算法就是最近邻居算法。
这个算法的cost是 O(N*log(N)) 而全动态编程的cost是 O(3N), 所以假如你有20个join,那么这个他们的对比就是26 vs 3486784401.差距很大吧,哈哈。
当然这个算法也有它本身的问题,就是我们有一个假设:两个表之间的最佳JOIN会让我们得到最终的最佳join。然后现实并不是如此的。要做这个优化,其实我们可以使用不同的规则来运行贪婪算法,从而找到最佳的计划。
好了,本文就介绍了一些对于多个表join是如何进行查询优化的,主要还是给大家一个感觉数据库究竟是怎样做的。



Recent Comments