Facebook是如何加速SQL查询
在PB级别的数据上进行查询是一件事,如何在Facebook这种级别的产品上使用则是另外一件事。今年早期时候,他们把Alluxio分布式文件系统集成到了他们的数据架构上,实现了存储和计算的分离,以此用来加速查询。
Facebook很早就使用Apache hadoop,并且到现在还可以在Facebook的架构中看到他。它们已经把数据存储从Hadoop clusters中移开了,但是仍然使用HDFS在Warm Storage中访问数据,这是一个由Facebook开发的定制的分布式文件系统,用来在分离Hadoop之后进行数据存储的。
Facebook内部使用了很多Presto来进行SQL查询,A/B testing以及服务一些关键的仪表,比如每日的活跃用户(DAU)或者每月的平均用户等等。作为一个没有存储模块的计算单元,Presto对计算和存储分离的架构非常友好。
为了让SQL查询的延时在一个可以工作的范围(比如在一秒左右),几年之前,Facebook实现了一个数据Caching的策略。Dubbed Raptor,这个系统要求用户在Presto cluster的SSD上创建ETL pipeline来cache数据。
Raptor加速了查询的速度,因为很多查询都再也不用通过网络了,但是同时也带来了很多别的问题。
开始的时候,把计算和存储放在一起,就限制了公司去把他们分开来扩展,这显然是不好的。它也导致了数据的碎片化,从而降低了用户的体验,这主要是因为查询有时会hit warm storage,有时会hit 本地SSD的cache。而且它也是的数据的安全和隐私保护更加复杂,因为你不仅仅要保护Warm Storage中的数据,还需要保护本地SSD的数据。
去年秋天,Facebook开发实现Raptor的替代方案。它是基于Alluxio,这个新的系统的查询性能和Raptor类似,但是不需要在SSD中cache数据。
Alluxio是一个虚拟的分布式文件系统,它连接了多个计算引擎和后端存储系统。它是由Haoyuan在UC伯克利 AMPLab开发的。Facebook基于Alluxio开发了一个新的版本,让它可以在Java上运行。
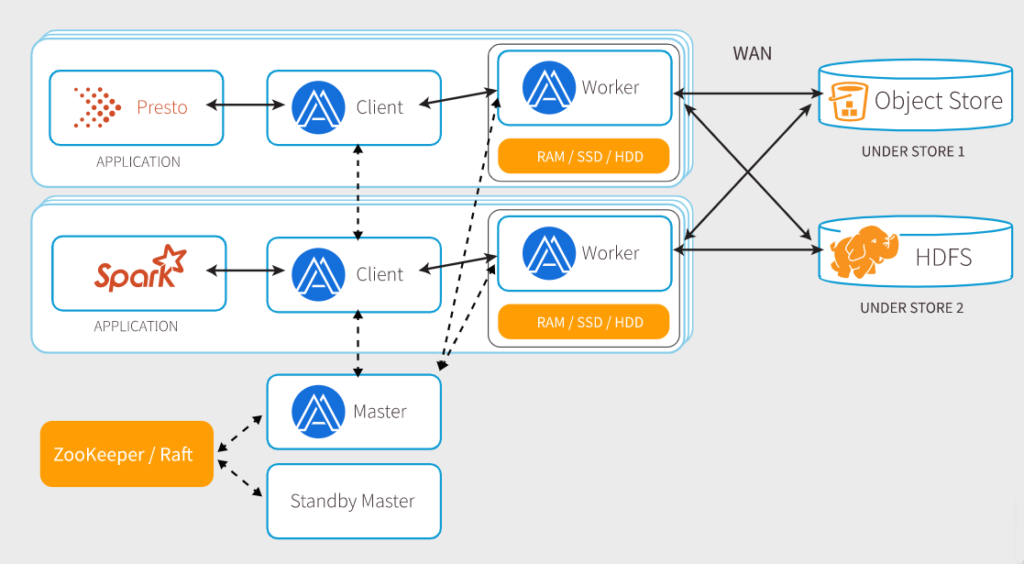
Facebook使用ORC文件格式来存储数据,并且通过HDFC接口来让Presto访问。Alluxio的实现可以在SSD上工作,并且把数据存储在本地,从而加速访问,但是本地的cache却不再需要了,而且Alluxio也可以在没有SSD的情况下使用Warm storage来加速访问。
当Alluxio在上百个Facebook数据中心的节点上安装之后,用户就可以体验到和之前Raptor类似的查询性能。它们可以使用很多Join的查询来查询PB级别的数据,没有Alluxio或者Raptor之前,这些查询可能需要超过10s才能返回。在一些能够hit oft-queried表格的查询,Alluxio可以相比Prestor负载提高了30%到50%,这显然是一个不错的提升。
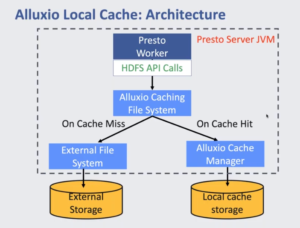
根据James七月份的报告,相比于Raptor,Alluxio cache减少了57%从远端数据存储单元读取的操作。Alluxio cache的hit rate查过了90%。
Jain说,现在还有一个问题,就是当有很大的数据请求过来的时候,就很容易让cache的hit rate降低,它们现在正在想办法解决这个问题。
这个方案的另外一个优点是金钱和安全,因为Presto计算单元和数据存储是分开的,这样可以分开进行提升,而不会有浪费。在安全性方面,也不需要再担心SSD上数据的安全,而只需要关注warm storage上数据的安全即可。
当然Raptor也没有完全被取代,不过预计在未来六个月会被完全取代。




Recent Comments