分布式系统之leader-followers Replication深入介绍
我们在前面有简单讲过Replication的作用,简单说就是为在多个机器上保存同样的拷贝来服务的。有了这个拷贝之后我们就可以做很多事情,比如说它可以成为一个读的源从而分散读的压力,它可以在原来数据机器出问题(或者deploy)等的时候作为一个backup等等。
这个想法其实很简单,但真正在我们做这个拷贝的时候,会遇到很多问题,比如说我们是使用同步还是使用异步来进行同步多个拷贝,如何保证多个拷贝之间的一致性等等。那么本文就来从各个方面详细介绍这些内容。
Leaders和Followers
我们把每一个保存数据的节点称之为replica,当我们有多个节点的时候,最明显的一个问题就是怎么去保证每个节点的内容都是一样的呢?其中最常见的方法就是基于leader的模式(也称为master-slave模式或者active/passive模式)。总得来说,它的工作方法如下:
- 一个节点是leader。所有的写操作都必须经过leader。
- 其他的节点我们称为follower,每次leader写数据的时候,也把相关的内容发送到每一个follower(replication log),然后每个follower根据这些log来更新本地的数据。
- 当有读的操作的时候,既可以从leader读也可以从follower读。

同步VS.异步Replication
上面这种方法其实在很多关系型数据库中很常见。这里遇到的一个最大的问题就是使用同步还是异步来进行replication。
就比如上面的这个case,它实现的功能很简单。就是把user id 1234这个用户的picture更新一下,它首先发送了update的请求到了leader的replica上。在这之后,leader会把这个更新的请求分别发送给两个follower的replica,从而最终达到所有的replica上这个用户的picture都更新了的效果。
我们就以这个例子来分析一下同步和异步在这两个上面的差别。如下图所示,我们看到leader的返回是在Follower1 更新完成之后,也就是说follower1是一个同步的更新。而leader并没有等待follower2完成更新再返回,这也就意味着follower2的更新是一个异步的。
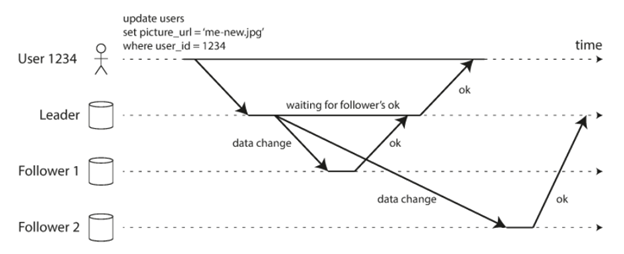
从这个图中可以看到follower1和follower2的更新其实都是有一个延时的,尽管大多数时候这个延时都很小,但是当我们遇到网络问题或者别的情况的时候(CPU占用率很高,内存不够等等),这个延时有可能会很大,谁也不能保证什么时候能被更新。
所以,同步更新的好处就是follower其实和leader是同步的,当leader有问题的时候我们甚至可以直接切换到同步更新的follower,当然它的问题也很明显,就是每一个更新(写操作)都需要等待这个follower的更新完成才行,这有可能会导致整个request延迟很久,甚至超时。所以,假如你想做同步的更新,一般来说也不会想让所有的节点都同步,而是选择leader和一个节点是同步的,这样就可以在leader出问题的切换和同步的效率之间达到一个很好的trade off。
当然,事实情况下基于leader的replication基本都是完全使用异步。这样的问题就是leader出问题,那些没有sync到别的node的数据就会丢失。好处就是leader完全不受别的节点的影响,哪怕别的节点都出问题也可以正常独立运行(通常这个时候就会出alert,然后oncall就到了表现的时候了,哈哈)。生产环境中这样的选择其实有很多原因,比如说为了保证随时都有节点是健康的,这些节点通常会分布在不同的地区(数据中心),所以他们之间的通信通常不是那么可靠,如果使用同步就会很容易出现问题等等。
Follower的建立
有时我们需要从无到有建立一个新的follower,这种情况在生产环境中特别常见,比如说机器的磁盘坏了,原有follower的数据就都不能用了,这个时候就需要从头开始建立,或者说某个时刻你没有足够的follower了(比如说数据中心出问题了,或者机器出问题了),你需要在一个新的机器上建立一个 follower,那么如何从头开始来建立一个节点呢?
首先想到的就是从leader上拷贝过来就好了,但是我们知道leader其实是在不停改变的,也就是说随时都在不停地被写入,而数据的拷贝速度不会很快(主要瓶颈在HDD的写入速度上,目前基本在200MB/s左右),所以在这个过程中不允许写可能也不是一个很好的方法。那么一般来说是怎么做的呢?大概会有以下的步骤:
- 得到一个数据库某一个节点的snapshot(这个snapshot不影响写)。大多数数据库都支持这样的功能。
- 拷贝这个snapshot到新的follower
- Follower联系leader去得到所有的在这个snapshot之后的操作(log sequence)。
- 然后follower根据得到的信息来apply snapshot之后 的操作,我们称这个过程为catch up。
处理节点的中断
我们上文中也提到了任何节点在任何时候都有可能出问题。那么要是真的出问题了,我们一般会怎么处理呢?
假设现在出问题的节点是follower,如果这个问题只是service crash或者server reboot,也就是说磁盘上的数据还是好的,那么我们常见的处理方法就是等到系统恢复过来之后,看一下磁盘中的数据库上次replay到了哪个地方(通常会保存在数据库的头信息中),然后根据收到的log(以及沟通leader得到server reboot这段时间的log)来继续replay,就和上面提到的catch up是一样的。
假如出问题的这个节点是leader,那么情况就稍微有点复杂了。因为这个时候需要找一个follower来成为新的leader,所有的写操作需要指向这个新的leader,别的follower也需要从这个新的leader来获取信息。我们称这个过程为failover。Failover可以是手动也可以是自动的,自动的failover有以下这些过程:
- 判断leader是真的有问题了。这就需要一些node down detection的机制,比如类似的心跳机制来判断leader是不是真的有问题,等到确定有问题了才来继续下面的步骤。其实这里如何进行detection是一个很好玩的话题,笔者在现实生产环境中也曾为这个问题伤过脑筋,比如你怎么判断是leader的问题还是你本身的问题,谁来决定leader有问题等等。
- 选择一个新的leader。这个通常有一个选举的过程,就是谁是最好的候选人,需要大家一起来决定,这里就有很多机制值得探讨,比如majority的election等等。
- 重新配置系统来使用新的leader。当新的leader选择好了之后就需要通知所有的traffic切换到新的leader来处理数据流了。
Failover的过程中其实会遇到很多问题:
- 假如我们使用的是async的方法来进行同步数据,那么新的leader可能是有数据丢失的。这个时候假如旧的leader回来了,他们之间就会有冲突了,如何处理这些冲突呢?一种常见的处理方法就是把旧leader里面的数据丢失掉,不过这样就相当于我们丢失了用户的数据。
- 丢失掉写的数据有时会有很大的问题,比如说我们是和别的系统相关联的,而这个丢失的写正好的别的系统很在意的,这样就会出现数据的冲突。
- 多个leader的情况,比如说原来的leader还认为它自己的leader,而新的leader也觉得自己是leader。这种情况我们称之为split brain。这就很危险了,因为两个leader都在接受写操作,然后还没有解决写冲突的机制,那么显然情况就会很糟糕。这个时候你就需要一个leader的monitor机制来确保不要同时有两个leader。
- 如何来决定leader有问题。这个是一个很难的问题,因为生产环境的网络其实有时很不稳定,你10s收不到心跳有可能只是一个网络的波动。假如你觉得10s是一个不能接受的阈值,那么你可能会一直在切换leader,假如你时间设置长了,就意味着真的出问题的时候,你在这段长的时间内就没法操作了。这里就是一个trade off有时需要结合现实情况来处理。
如何实现replication的log
我们在上面一直说可以根据leader的log来catch up,那么这个log怎么产生呢?一个简单地的实现就是数据库的每一个操作产生一条log,这样follower就可以根据这个log来重复相应的操作,比如INSERT,UPDATE等。这个实现乍一听起来还不错,但一细想就会发现好像有点问题:
- 任何调用不确定的数值都会有问题,比如说NOW()或者RAND()函数,假如你只是传递相关操作,那么在两个机器上执行的结果就会有差别。
- 假如操作取决于别的条件,比如UPDATE..WHEN,那么就需要所有的log执行的顺序是一模一样的,不能有任何差别
- 状态相关的内容可能会在不同的server有不能表现。
当然这些问题都是可以解决,比如说我们可以把RAND()替换中真正得到的数等等。
往前写的log
我们在之前有聊到过,很多时候数据库本身把数据写到磁盘,还会实现一个一直往前写的log,用来防止磁盘写发生问题,从而可以恢复。这里我们其实也可以把这种log发送给follower,这样每一个follower就可以根据这个log来catch up。
逻辑log的replication
还有一种常见的log就是逻辑log,它和数据库引擎使用的log不同,基本实现如下:
- 假如insert一行,log就包含插入行的所有列的数据。
- 假如delete一行,log就包含足够的区分行的信息。
- 假如更新一行,log包含做够区分行的信息以及需要所有的更新后的列信息(或者至少修改的列信息)
总结
至此,本文就总结了leader-follower这种形式的结构是如何运行,以及错误发生时的处理机制,最后还介绍了几种常见的replication的方法。




3 Responses
[…] 我们在《分布式系统之leader-followers Replication深入介绍》中深入介绍了replication了基本实现,本文主要来聊一聊replication lag常见的一些问题。 […]
[…] 通常来说为了更好地达到replication的目的,我们需要有最少3个replica,他们最好能分布在不同的数据中心(位置)。这样即使有灾难发生,比如地震等等,我们也能保证有至少一个repica是可以使用的。有关replication的基础知识可以参见这篇文章《分布式系统之leader-followers Replication深入介绍》。 […]
[…] 我们在前面的《多leader replication的实现及常见问题介绍》和《分布式系统之leader-followers Replication深入介绍》分别介绍了多leader和单leader的情况,也许你会好奇是否有无leader的实现呢?答案是肯定的,本文就来深入介绍无leader replication的实现和相关的问题。 […]