分布式系统简介(总论)
我们在前面几篇文章中简单介绍了单个服务器对数据的处理,而在现实中数据的存储和获取会涉及到多个机器,也就是说我们会把数据分布在多台机器上,这样做有很多好处:
可扩展性(Scalability)
随着你的数据增加,一个机器可能很难处理日益增长的读写需求,你可以把这些负载分散到多个机上。
容错性/高可靠性(Fault Tolerance/ high availability)
在现实环境中,任何一个机器都有可能出现故障,可能是磁盘故障,网络故障等等,假如你希望某一个或几个机器出现问题,你的产品仍然能够继续工作,那么就需要分布式系统。
延迟(Latency)
假如你的用户遍布全球,那么你肯定希望让你的服务器物理上更加靠近对应的用户,这样才能减少相应的延迟。
总得来说,就像我们之前介绍的,当需求增加的时候,你就需要进行扩展,要不是垂直扩展,增加机器的处理能力,要不就是水平扩展,使用更多的机器来处理。前者有尽头,后者则无涯。具体可以参见我之前介绍的《负载均衡》。
Replication和Partitioning
我们在之后将重点来介绍如何水平扩展,通常来说有两者方法来实现水平扩展:
Replication
这种方法就是在多个节点(机器)上存放同样的数据,并把它们分布到不到的地方(防止自然灾害等),当一个或几个节点出现问题的时候,保证仍然能有一个节点可以工作。同样的这样的处理也能提高性能。
Partitioning
所谓的partitioning就是把一个大的数据分块存在不同的节点上。
它们两相互是独立的,不过通常我们会同时使用它们,具体的如下图所示:
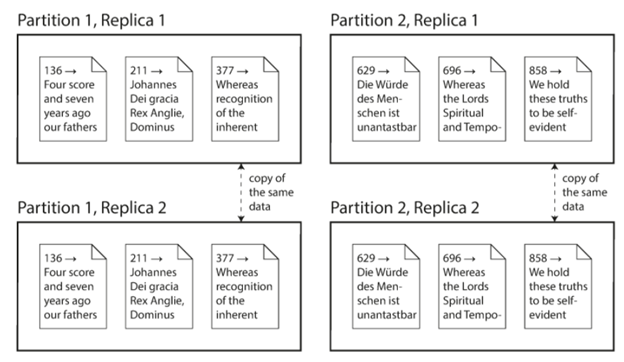
我们将在后面的文章中来具体详细地介绍如何做replica,如何做partition,以及如何处理数据读写过程中发生的常见问题等。




Recent Comments