
关系型数据库进阶之数据管理
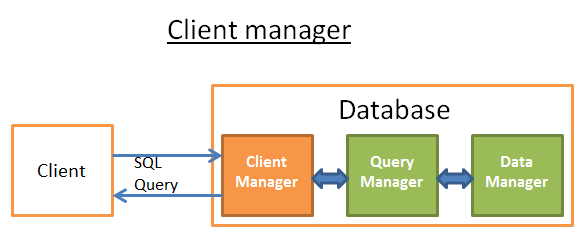
我们在前面已经介绍了客户端管理,查询管理,今天来介绍数据管理。 在这一步中,查询管理会执行相应的查询,这个时候就需要从表和index中得到数据了。它需要数据管理来获取数据,不过这里有两个问题: 关系型数据库使用的是transaction的模式,所以你不能够在任何时候都得到数据,因为同时可能有别人在使用或者修改数据。 数据的获取是数据库中所有操作最慢的操作,所以数据管理需要足够聪明,来把数据保存在内存buffer中。 本文我们就会来讨论关系型数据库是如何处理这两个问题的。...






Recent Comments