ElasticSearch进阶之输入匹配
我们在日常使用搜索引擎的时候会发现随着我们的输入,会出现一些可以选择的提示,如下图所示,我们称之为即时搜索或者输入搜索。本文就来讨论一下,ElasticSearch在这个方面是如何实现的。

就像上图所示的,在我们输入了johnnie walker bl之后,可以立即显示一些建议,比如johnnie walker blue label等等。我们下面就来详细介绍一下实现这个效果的几种方法。
前缀搜索
在正式介绍之前,我们先来看一种搜索,称之为前缀搜索。也很好理解,比如说我们想搜索所有以W1开始的单词就可以使用下面这个搜索语句:

前缀搜索其实是在term这个级别进行处理的,说白了就是我们以前的搜索是直接在inverted index中找到搜索的term,而这次我们不是直接找term,而是一个个看term是否start with我们要查询的内容。
假设我们有一个inverted index,如下所示,那么在我们查询W1的时候,就会一个一个地进行检查,看它是不是以W1开始的,比如第一个SW5显然就不是,而第二个W1F则是的,所以就把它对应的Doc IDs收集起来,然后继续往下查询。

很显然,这种方法很简单,但是效率也很低,假如我们有几百万这样的inverted index,一个一个遍历显然效率很低。那是否有什么好的方法可以解决呢?答案也是有的,我们在后面来慢慢介绍。
查询时处理输入搜索
在介绍优化的方法之前,我们来看看前缀搜索是如何应用在输入时匹配的。我们在之前的《ElasticSearch进阶之邻近匹配》中讲过如何进行多个term的搜索。而这里比较类似,针对Johnnie walker bl的自动补全,我们也可以使用一种称之为短语前缀匹配的方式,如下所示:

这个查询包含了下面几个方面:
- 首先查询的单词是johnnie
- 在这个单词后面跟着的是walker
- 再后面跟着的是一个以bl开头的单词
为了保证这个先后的顺序,我们可以加上之前邻近匹配中提到的slop参数,如下所示:

根据之前的slop的定义,这里其实也是允许顺序颠倒的,只要距离是我们可以接收的范围就可以。但是不管顺序如何颠倒,只有最后一个单词bl进行前缀匹配,不会进行别的单词的前缀匹配。
前缀匹配是有一个问题的,比如我们只输入了bl,会有很多单词与之匹配。这里我们就可以通过max_expansions来进行一些限制,如下所示,max_expansions可以控制允许多少个term进行前缀匹配,当超过这个数字时就停止进行前缀匹配了。

上面这种搜索的方法都是在查询时候进行处理的,相对来说其实效率并不是特别高。
Index时优化
上面提到的查询时处理的优点很明显,就是不需要做任何额外的操作,只要在查询时处理就好了。但那是缺点也很明显,就是效率不是很好。假如我们对查询的性能要求比较高的话,比如说搜索引擎中的边输入边显示结果,你不可能等个几秒再返回,那时候用户说不定早就自己输入完成了。这个时候就有一个优化方法,那就是在index的时候先做一些处理,从而使得查询变得快捷很多。
当然在index时进行处理也有其自身的问题,就是你会使得index的size变得很大,index的速度也会有所影响,但总得来说得到的查询performance的提升还是很值得的。我们下面就来看看index的时候是如何处理的:
n-gram处理
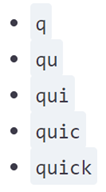
n-gram处理的思想很简单,就是我们在index的时候就预先把某一个term处理成可以模糊匹配的形式。比如quick这个单词我们可以在index的时候进行如下处理:
- 长度1(unigram): [q, u, I, c, k]
- 长度2 (bigram):[qu, ui, ic, ck]
- 长度3(trigram):[qui, uic, ick]
- 长度4(4-gram): [quic, uick]
- 长度5(5-gram): [quick]
显然对于我们这种输入查询并不需要这么复杂,我们只要进行边界的处理就可以了,我们称之为edge_ngram,它处理之后的结果如下所示:
这样一来我们就可以在index的时候使用下面参数,这里就是使用了edge_ngram:

然后在analyzer中设置这个filter

这样一来,就会首先使用standard tokenizer来进行tokenize每一个term,然后再使用edge n-gram来进行处理。
这样处理之后,我们在查询的时候只要使用正常的匹配查询就可以了,比如说我们有一个”brown fox”的短语,它在处理之后fox这个单词就会变成f,fo,fox,那么当我们输入brown fo的时候,使用下面的查询就可以了:

这里其实就是找brown fo两个term就可以了。因为我们在index时候进行了edge n-gram的处理,所以它很容易就匹配到brown fox这个短语。
Completion Suggesters
其实除了上面提到的这种根据term来搜索的方法,ElasticSearch还有一个专门针对这个场景的功能,我们称之为Completion Suggesters。顾名思义,它就是用来快速建议完成一个单词的,所以速度是它的第一优先级。它其实使用的是一个支持快速查询的数据结构,这个数据结构保存在memory中,只有这样才能够达到快速的目的。
它在index阶段就把所有可能的completions都feed进来,然后构造一个有穷的状态转换器,它有点类似一个大的图。然后每次查询的时候,就是一个一个字符在这个图上的各个path进行顺序查找,当把所有的用户输入都查找完成之后,它就可以显示所有的图的edge,也就是对应的suggestion(是不是很像一个leetcode的面试题,哈哈)。
所以一般来说,会在index的时候feed有可能的completion:

在查询的时候如下所示:
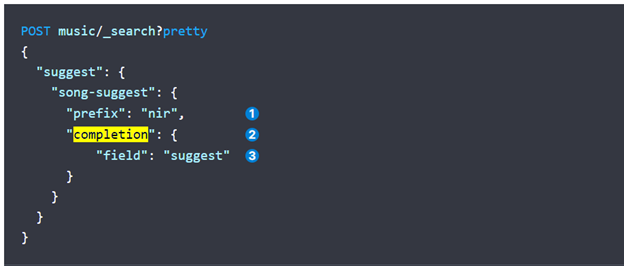
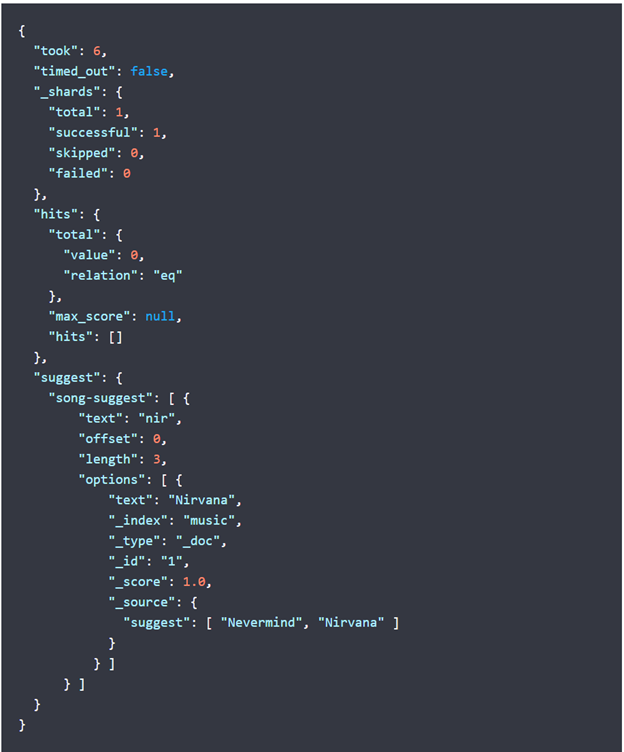
结果如下所示:
总结
本文介绍了ElasticSearch是如何进行输入匹配的,它包含了查询时处理和index时处理两种方法以及最后的completion suggesters。希望能对你理解相关方面有所帮助。




Recent Comments