ElasticSearch进阶之拼写错误
我们在搜索时经常会出现拼写错误的情况,那ElasticSearch有没有什么可以处理这个问题的技术呢?本文就来介绍两种方法,一种是查询时候的模糊匹配(Fuzzy matching)。另一种是index时候的语音匹配(sounds-like matching/Phonetic Matching)。
模糊匹配概述
模糊匹配简单来说就是假如两个单词看起来类似,我们就认为他们是一个单词。这里的关键就是怎么来判断这两个单词是类似的。早在1965年,Vladimir Levenshtein就发明了编辑距离(Levenshtein distance)用来测量从一个单词变到另外一个单词需要多少次的编辑。在最初的版本里面定义的每次编辑包含下面这三个操作:
- 从一个字符改成另外一个字符,比如book->cook,这里就是把b变成了c。
- 插入一个新的字符,比如boo->book,这里就是在末尾插入了一个k,当然可以在任何位置插入。
- 删除一个已有的字符,比如black->back,这里就是删除了l。
后来Levenshtein可能发现忽略了一个更普遍的拼写错误的情况,于是加入了一个新的操作:
- 交换两个连在一起的字符位置,比如tkae->take,这里就把k和a两个字符的位置进行了交换。
有了这样的定义,就可以用这个距离来判断两个单词之间的编辑距离了。有研究发现,大概80%左右的拼写错误之间的编辑距离都只有1,ElasticSearch在模糊匹配的时候可以通过设置fuzziness这个参数来改变最大支持的编辑距离,比如设置为1,你就可以cover大概80%的拼写错误了。
只是假如你仔细思考一下,单纯地设置编辑距离看起来并不是一个很好的方法,因为不同长度的单词对这个编辑距离的敏感度是不同的,比如一个单词bad,设置成编辑距离2的时候可以变成hat,或者别的各种完全不相关的单词,因此fuzziness这个参数支持一个AUTO的设置,它表示:
- 当字符串只有两个字符的时候是0
- 当字符串有三,四或者五个字符的时候是1
- 多于五个字符的字符串设置为2
Fuzziness的默认值就是AUTO。
模糊匹配示例
下面我来看一个实例,假设我们的index里面有这些文本:

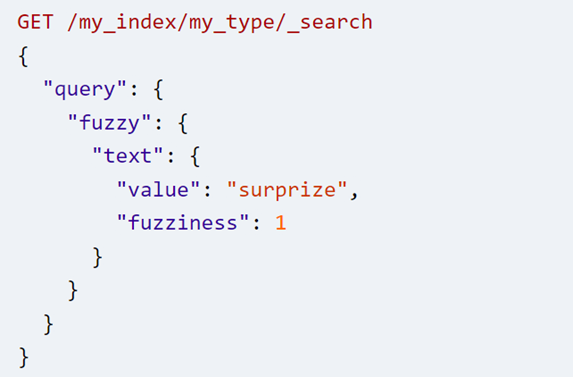
我们可以用下面的模糊匹配来查询surprize (s写成了z,算是一个很常见的拼写错误)

模糊匹配是一个term level的查询,不会做任何analysis,因为默认值是AUTO,而我们查询的字符串大于五个字符,所以其实使用的是编辑距离2。因此文档1和3都会返回。假如说返回了太多不相关的内容,我们可以把编辑距离设为1来只返回文档1,如下所示:
性能优化
模糊匹配的实现机制很简单,就是首先会找到查询term在规定编辑距离内的所有单词,我们称之为Levenshtein automaton。然后再使用这个automaton去查询有哪些是符合要求,从而得到匹配的文档。这样的做法问题就在于哪怕是编辑距离设为2的时候,也需要查询很多term,从而性能比较差,有两个参数可以用来优化这个问题:
- Prefix_length:这个参数是用来设置前面几个字符串不做模糊查询,这个设置是基于现实情况来设置的,一般来说我们拼写错误不会发生在开始的几个字符,或者说更大概率会发生在后面几个字符,因此假如我们让前面几个字符必须是一样的,比如设为3就意味着需要查询以这三个字符开始的单词,这样我们的Levenshtein automaton就会小很多,从而提高性能。
- Max_expansions:假如模糊匹配查出了两三个可能错误拼写的单词,那么这种模糊查询就比较有效果,但是假如说有几千个都匹配其实也就没有啥意义了,因此我们可以通过这个参数来设置最大的匹配结果。这样也可以有效提高效率。
模糊查询score
有人可能会觉得模糊查询很好啊,我们可以把它作为score的一部分来和别的查询结合以得到一个更精确的分数。但是假如你仔细研究一下会发现模糊查询的默认score其实是被设为一个常量1的,也就是说不会影响最终的结果,这是为什么呢?
主要原因还是考虑到文档中的拼写错误,比如我们查询surprize,假如有1000个文档包含了正确的surprise,但是有一个文档中就是包含了这个错误的输入surprize,那么根据我们之前在《Elasticsearch基础之相关性介绍》中介绍的TF/IDF的算法,这个错误输入的分数就会比别的高出很多,而这显然不是我们想要的结果。因此最好不用使用模糊查询的score。
语音匹配
我们家小朋友有时会知道某个单词怎么读但是不知道怎么拼写,这个时候他就会尝试用他知道的发音来组成一个“新”单词。对于这种单词其实ElasticSearch也是可以通过一些方法来进行处理的。它主要会在index的时候根据一些库来得到发音类似的单词,然后再编到index中。目前不同的语言有很多不同的库可以支持,基本都是基于soundex算法的,比如Metaphone或者double metaphone,Gaverphone,beider-more算法等。不过总得来说这些库都还比较粗糙,对英语相对来说比较好一点。
要使用这个功能,你首先需要安装语言分析的插件(https://github.com/elastic/elasticsearch-analysis-phonetic),然后再创建一个客制的analyzer来使用它,如下所示:

这样一来你就可以和其它的analyzer一样使用它了。因为它在index时进行处理,相对来说在查询的时候性能基本就可以很好地进行保证了。
总结
本文介绍了两种对拼写错误的处理,主要介绍了模糊查询的机制和使用方法,希望对大家有所帮助。




1 Response
[…] 可以参考东哥的这篇博客:ElasticSearch进阶之拼写错误。 […]