Kafka进阶之MirrorMaker介绍
我们在之前聊到Kafka内部各个节点之间会通过replication来拷贝数据以保证high availability。现实中还有一些使用场景就是需要在不同的cluster之间连续拷贝数据,我们称之为mirroring,Kafka内部有实现这样的功能,这就是本文要来聊一聊的MirrorMaker。
使用场景
也许你会好奇,究竟有哪些使用场景会要用到MirrorMaker呢?我们来举几个例子中:
- 各地和中心cluster,有些公司在不同的数据中心拥有一个本地的cluster,很多时候应用只需要在一个数据中心进行处理就可以了,但是有时有某些应用希望访问多个数据中心的数据,比如说一个供应链的价格数据,每个数据中心都有他们本地的供给价格,然后我们又希望能有一个全公司的价格分析,这样就需要把所有数据中心的数据都复制到中心cluster进行分析处理。
- HA和灾难恢复(DR):有时我们的cluster在一个数据中心就可以了,它完全没有多数据中心的需求,但是为了防止这个数据中心出现问题,我们还是希望能够有第二个数据中心能有完整的数据来提供HA和DR。
- Cloud的迁移,现在有很多厂商都在向cloud上进行迁移,但是这个迁移肯定不是一下子就能完成的,在这个过程中如何做到原来on-premises cluster和云cluster之间的同步,就需要MirrorMaker的功能。
多cluster架构分析
在我们深入分析之前,先来看看一些常见的跨数据中心交互的方法以及他们的trade-off。
Hub-Spoke架构
这种架构主要是为了多个本地cluster和一个中心cluster的架构服务的,如下图所示:
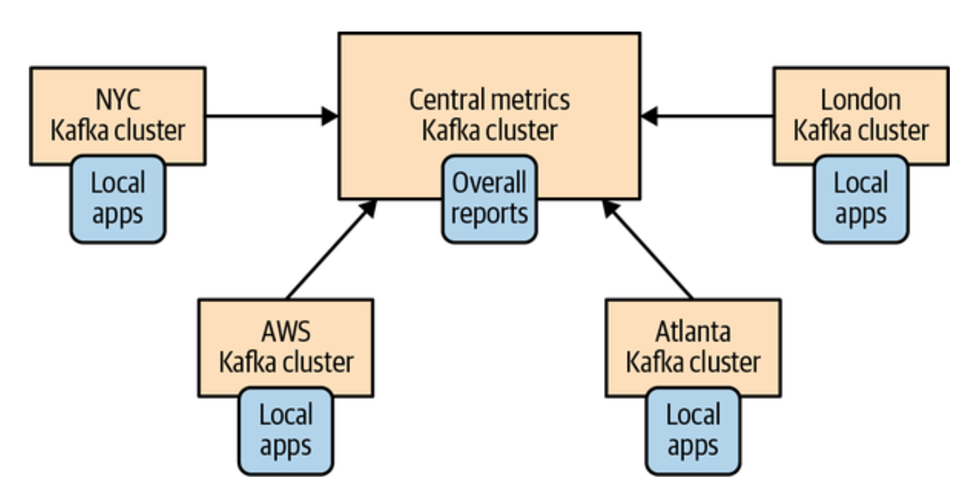
总得来说这种架构就是本地有自己的cluster,各个本地的应用可以从本地的cluster进行读写。各个地区的cluster会统一到中心cluster,要访问所有cluster的数据必须从中心cluster进行访问,各个本地的应用是不可以访问中心cluster的。
这种架构的好处就是数据只从各个local cluster到central cluster,所以是单向流动的,而且consumer也只会访问本地cluster的数据,所以相对独立,我们处理起来也很方便。
它的缺点也很明显就是没法进行cross数据中心的访问,也就是说一个location内的processor是没法知道别的cluster的内容的,只有中心cluster才能访问所有的内容。
Active-Active架构
这种架构如下图所示,就是每个数据中心既可以当produce也可以当consume。

这种架构就解决了上面Hub-Spoke架构的问题,因为其实每个cluster都有所有的数据,因此每个consumer都能访问到所有的数据,由此也带来了另外一个好处,就是真的有某个cluster完全出问题了,我们也可以fail over到另外一个cluster。
这个架构最大的问题就是怎么处理数据的冲突,或者说保持数据的一致性会变得比较困难。比如说:
- 一个用户刚写了一个数据到某个数据中心的cluster,然后紧接着又从另外一个数据中心进行读,假如这个写还没有到另外一个数据中心,这里读到的数据就会不一致。所以有时为了解决这个问题会尽量要求一个用户大多数时候都使用一个数据中心的cluster。
- 又比如一个数据中心的event说用户买了一本书A,另一个数据中心的event说用户在同一时间买了一本书B,那么我们该如何处理这两者之间的冲突了,可能需要结合具体的应用来进行具体分析才行。
所以说,假如你能够很好的对这些冲突进行处理,那么现在这个架构就是更值得推荐的。还有一个问题就是你需要防止死循环地进行mirror,因此可能需要加入一些额外的标志来避免重复replicate。
Active-Standby架构
有些时候从business的角度来看,其实你没有必要去进行多数据中心的mirror,因为你所有的traffic都来自于同一个location,唯一的理由让你来做这个mirror就是做灾难备份,防止真的有什么事情发生的时候,还有一个相对完整的数据可以被使用。这个时候你就可以选择下面这种架构:

这种架构的好处就是你什么都不需要担心,就是创建一个standby的cluster默默接收数据就可以了,它也不会有人写也不会有人读,所以也不需要担心任何conflict等等。
当然这个架构的缺点也很明显,就是你有一个相对比较好的cluster,但是你大多数情况下都不会用到它,浪费金钱也浪费资源,哈哈。而且因为它其实不是那么的完美,很多时候只能当作最后的救命稻草,不能真的被随时拿来做failover的target(会有数据的丢失等等问题)。当然当你真的想用这个cluster的时候,其实也会有一些问题需要处理,这个是另外一个story,我们以后可以专门详细聊一聊。
Stretch cluster
看了上面这种Active-standby的架构之后,也许你会有疑问,为什么一定要加一个新的cluster啊,我能不能在不同的数据中心加一个replication,只要我能保证这个replication是同步sync的就可以保证即使一个数据中心出问题了,我也可以通过这个replication恢复了。其实这个在Kafka 2.4.0之后,我们甚至可以让consume就近从相应的location的broker中读取数据。
这种方法对那种要求DR的数据必须保证和之前cluster是100%同步的情况下很有效,因为你可以通过cluster的ack设置+min.insync.replicas来得到这个效果。当然相比于Active-Standy的架构,也没有被浪费的资源,所有的broker都可以被使用,也算是一个优点吧。
缺点也很明显,就是它真的只能防止数据中心的灾难问题,对于cluster本身的问题不能处理,因为它们都位于同一个cluster中,只要这个cluster有问题,那么整个架构都会出问题。
Kafka MirrorMaker
在了解上面这些常见的处理方法之后,我们来看看Kafka支持的MirrorMaker是怎么一回事。MirrorMaker的目的很简单就是把数据在两个数据中心的不同cluster上同步。早期的版本其使用的是一个consumer group中的consumer作为中转,它接受第一个cluster的数据,然后把这些数据再发送到目的cluster上。这种方法最大的问题就是延迟有时会很长,尤其是有新的topic加入的时候很容易出问题。所以后期其实使用的是Kafka的connect架构来实现的,只要简单进行配置就可以实现了。它的简单架构如下图所示:
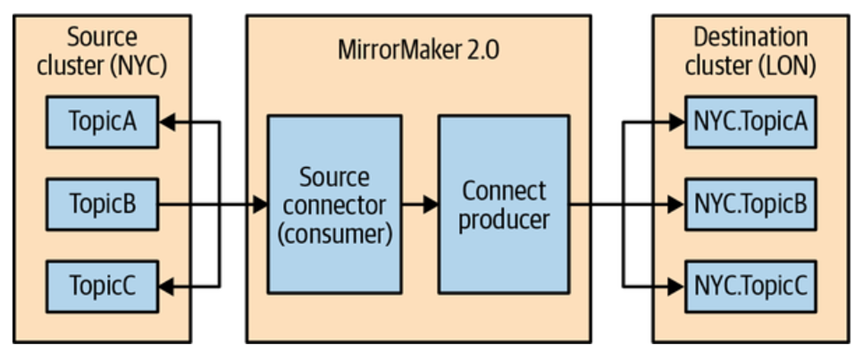
这种方案有很多优点,比如说在source添加了一个新的topic,它会自动在destination那边也创建一个对应的topic。而且你可以通过简单的config来配置你是使用我们上面提到的hub-spoke还是active-standby抑或是active-active的架构。上图其实就是一个active-standby的设置。
下面就是一个简单的从NYC到LON的cluster的mirror的设置:

3中设置的就是一个NYC到LON的mirror,它是一个source->target的格式,4中就是设置所有的topic都需要进行mirror。当然还有更多的设置方法可以参考相关的官方文档,这里就不一一列出了。
总结
本文介绍了MirrorMaker的基本概念和背后的各种思想,希望对你理解相关概念有所帮助。




Recent Comments