Kafka基础介绍之消息commit
我们在《Kafka基础介绍之Consumer》中有提到可以使用poll函数来获取消息,而每次调用poll函数的时候,它返回的其实是Kafka中你这个consumer所在group还没有读的message。那这个还没有读是通过什么来判断的呢?它在Kafka中是通过offset来决定的,本文就来详细和大家聊聊Kafka中是如何通过offset来进行commit的。
概述
Kafka中consumer是通过offset来track每个partition中读的位置的,和一般的Queue的处理有些不同,在Kafka中你不需要每个message都进行commit,你可以一段一段地进行commit,也就是说假如Kafka收到你对offset 9的commit,那么它会默认你已经接受了9以前的所有的信息,而不需要你对8,7,6等都进行commit。
这种commit的方式在正常情况下是没有问题的,但是当出现我们以前提到的rebalance的情况,比如说consumer crash的时候它就只能从上次commit的offset来进行处理,举几个例子:
比如说我们上次commit的offset是2,也就是说2之前的数据我们已经commit说收到了,现在我们还在继续通过poll读取数据,读了3,4,5,6也处理完了,但是没有commit,继续读了7,8,9,10,11正在处理10,这个时候出现了rebalance,因为你3-10并没有commit,所以新的consumer会从3重新开始,也就意味着3-10的数据其实是被重复处理了两次的。

当然还有另外一种情况会发生,就是你commit了一个offset,但是事实上你还没有来得及去处理它,这种情况下处理和commit之间的消息有可能就会miss掉了,如下所示,你已经commit了11,但你还在处理5,当有rebalance发生的时候,新的consumer会从11后开始处理,那么5和11之间的数据就相对于丢失了。

所以如何来进行commit影响还是蛮大的,下面我们来看看常见的几种commit的方式。
自动commit
自动commit是最简单的方法,你只要把enable.auto.commit=true就可以了,这样一来consumer会默认每5秒钟自动进行一次commit。当然你可以通过auto.commit.interval.ms来设置这个commit的间隔时间。
既然这种方法很简单,那它必然也有其局限性,比如说我们使用了默认的5s间隔进行commit,那么假设现在consumer是在上次commit之后3s crash了,在rebalance之后是不知道我们已经处理过这3s的数据的,它还是会从上次的commit的地方进行重新处理,也就意味着我们会重复处理这3s的数据。当然我们可以缩短这个5s间隔来降低这个问题出现的概率,但是完全避免是不可能的。
自动commit的做法是在poll循环中做的,也就是说本次poll commit的其实是上次poll得到的数据,正常情况下是ok的,但是当出现exception或者特殊退出循环的情况需要特别注意。而且这种commit的方法中开发者并没有什么办法来控制并避免重复的消息。
Commit当前的offset
很多时候我们想要自主控制什么时候去commit这个offset,Kafka提供了一个API给我们,我们可以利用它来自由地定义什么时候commit一个offset。当然前提是我们要把auto commit disable了。
最简单的API就是commitSync(),它会commit poll()函数返回的最新的offset,假如commit fail了就会throw一个exception。需要注意的是这个函数会commit最新的offset,也就意味着假如你没有处理这些数据就commit了,那么你就会有丢失数据的风险。但是假如你在处理数据之后进行commit,然后在处理数据的过程中crash了,那么你已经处理了的数据就有可能被处理了两次。这个trade off就是你需要根据你的应用来进行仔细考虑的。
下面是一个在处理完成之后commit的代码示例:
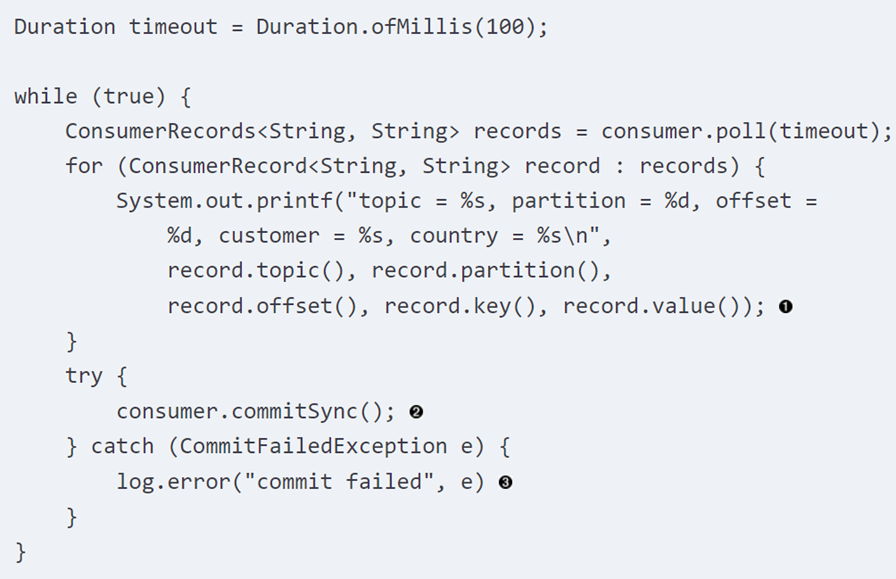
这个示例中假设我们处理数据的流程就是打印出来,所以在打印了所有的数据之后调用了commitSync()的函数,但是假如打印过程出错,在rebalance之后已经打印了的数据就会被再次打印了。
异步commit
上面这个commit的调用有一个比较大的问题就是它是同步的,也就意味着你需要等待它返回之后才能执行下一个循环,这样一来其实速度就会有所限制,那么有没有一个API能支持异步调用呢?答案也是有的:commitAsync(),相应的代码示例如下所示:

需要注意的是这个API有几个问题,第一个问题就是它增加了我们在发生问题时候的duplicate处理的概率,因为我们没有等待commit的完成,所以其实有可能在你crash的时候好几个commit都没有完成,在crash发生之后的你可能会重复处理所有这些数据。
第二个问题是async的commit不会重试,主要原因是防止commit的backward,比如说你commit offset 10的时候call fail了,这个时候后面有个commit 20的call成功了,假如你重试commit offset 10的call有可能会把commit设置回10。所以kafka就简单地没有进行重试,也许你会说加一个判断就可以解决这个问题了。其实不然,因为Kafka的commitAsync()还支持一个回调函数,所以commit的顺序其实是很重要的,如下面的例子所示:
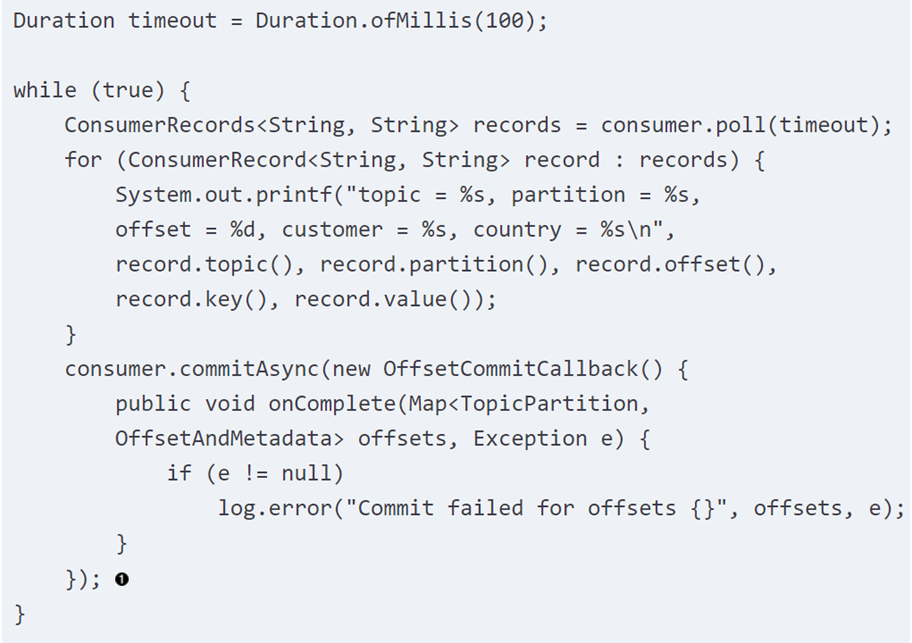
这里有一个回调函数,当commit失败的时候就打印一条log。
同步和异步的结合
通常来说,假如我们的poll()循环在继续,那么其中某次commit的失败是没有关系的,因为后面的commit会覆盖前面的commit。但是在循环结束或者发生什么exception的时候,我们希望我们的commit能真正的执行成功,所以有一种做法就是在循环中使用异步来提高速度,在退出循环的时候使用同步来确认commit成功,相关的示例代码如下所示:

Commit任何一个offset
我们上面提到的所有的函数默认都是commit最新的offset,假如我们的poll()函数包含了很大的batch,我们想在中间随时能够进行一些offset的commit,该如何做呢?其实上面的函数也是支持你传递参数的,参数是一个partition和offset的组合,因为一个consumer可能会consume不同的partition,所以你需要把partition的信息也传入进去,如下面的例子所示:
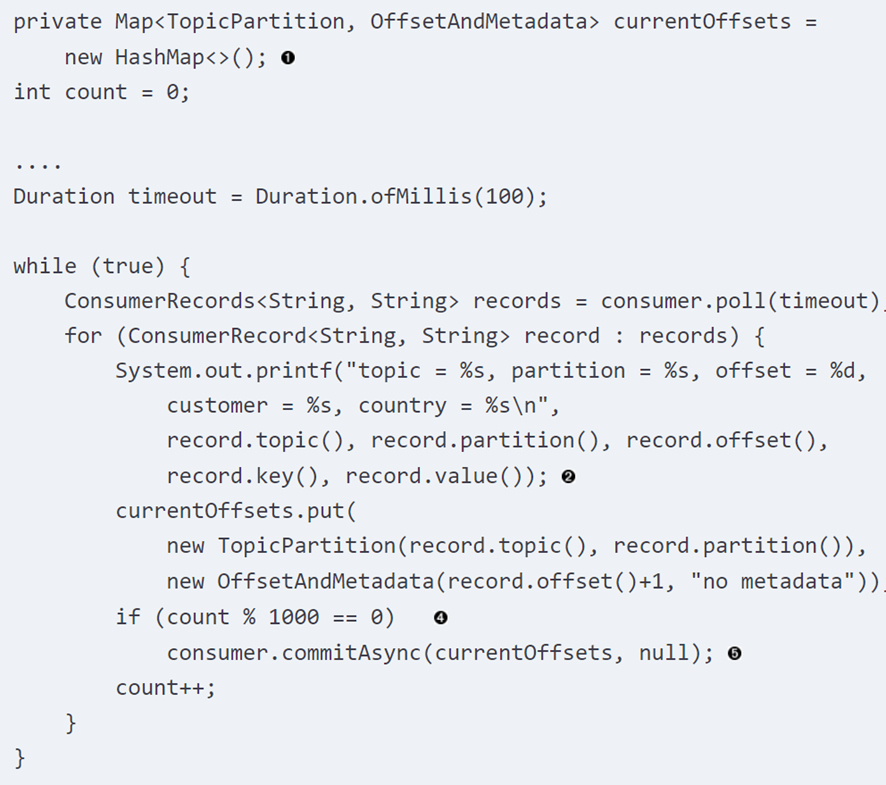
这个例子就实现了每1000个record就进行一次commit的功能。
总结
至此,我们把Kafka中commit相关的内容,包括同步,异步commit以及两者的结合和特殊offset的commit都介绍完毕了,希望对你理解相关的内容有所帮组。




Recent Comments