MongoDB和Couchbase analytics(解析)的对比分析
计算的目的是背后的洞察而不是数据本身 — Richard Hamming
所谓的商业运行就是一个分析哪些需要改变,该改变成什么然后据此改变商业本身的螺旋上升的过程。作正确的分析,你就如滚雪球般不停上升,反之,则不断的螺旋下降。
Couchbase, 是一个诞生在web 2.0世界中的一个新NoSQL系统,能够满足高扩展性,高性能以及高可靠性的要求。从最简单的键值对到复杂的大规模查询,搜索以及解析,Couchbase都可以很好的处理。而这些都是通过在Couchbase的多维架构中集成特定的引擎来实现的。其中查询和解析服务都是通过N1QL来进行交互的,为什么要用同样的语言来建造两个完全不同的引擎?这是因为:
“一刀切”的时代已经一去不复返了 — Michael Stonebraker
查询引擎是为了正常的操作工作来设计的,而解析引擎则是为分析操作来设计的。我们在之前的文章中曾对这两者进行过比较并给出了对应的建议。MongoDB也是通过同样的路径来处理类似的查询和解析操作的。
去年,MongoDB也官宣了它们为分析流程而实现的解析节点,本文将对两种解析引擎的使用场景进行比较和分析。
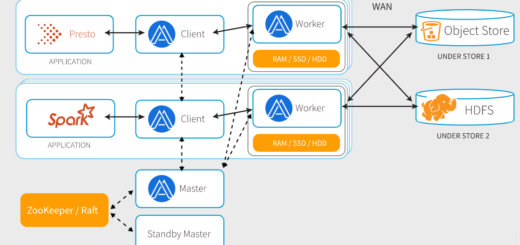
Couchbase的高层架构
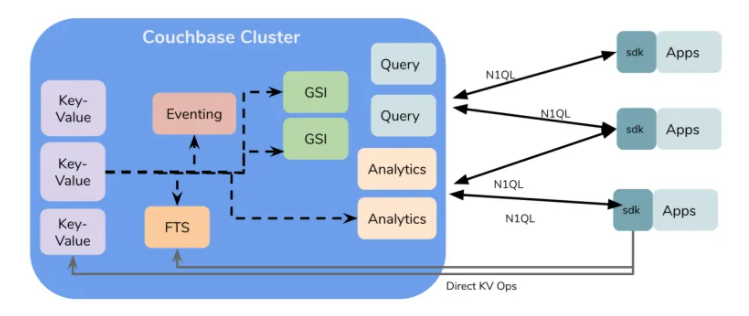
Couchbase内建解析器:高层架构
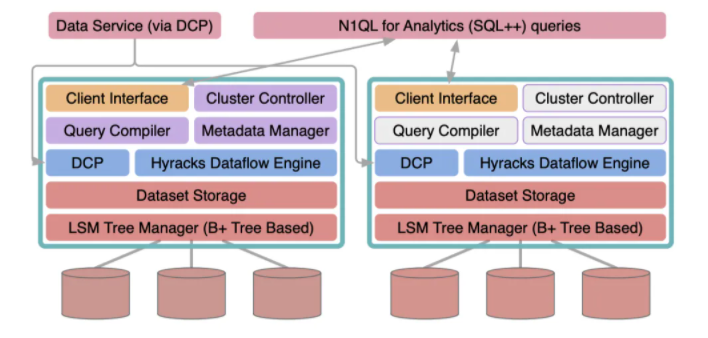
MongoDB解析节点:
下面我们来比较一下MongoDB解析节点和Couchbase解析所支持的特性:
| MongoDB解析节点 | Couchbase解析 | |
| 文档 | https://docs.atlas.mongodb.com/reference/replica-set-tags/ | https://docs.couchbase.com/server/6.5/analytics/introduction.html |
| 架构 | 使用一个次要的备份节点拷贝所有的操作数据,查询的语言是一样的(MQL),查询的过程和真实的操作过程是一致的 | 解析的节点是独立的,它拥有的数据是支持用户自定义的一个真实数据的子集。查询的语言也是一样的(N1QL)。查询的过程是专为更大的数据而设计的(具体见下面) |
| 架构细节 | Atlas Mapped Analytics Nodes | Couchbase Analytics: NoETL for Scalable NoSQL Data Analysis |
| 数据模式 | BSON | JSON |
| 查询语言 | MQL – MongoDB Query Language | N1QL – Non 1st Normal-form Query Language; SQL for JSON |
| 查询页 | MongoDB Query | Analytics Query |
| 查询过程 | 和正常的操作查询是一样的,使用mongos和mongod进行分布式查询 | 解析引擎专门为大规模并行处理数据进行设计 |
| 查询的优化 | 形状优化(Shape-Based Optimizer); 需要计划管理 | 规则优化(Rule-Based Optimizer)无需计划管理 |
| 解释 | 文字和图形 | 文字和图形 |
| 索引 | 需要创建正常操作的索引并拷贝过来 | 只需要解析相关的索引就可以 |
| 并行处理 | 每一个Ongod节点运行基本的操作并且mongos与之相组合(比如group和aggregation操作) | 为了能够更有效地处理解析查询,达到更好的扩展和性能特性,解析服务引入了同样的基于state-of-the-art,shared-nothing MPP的处理机制。具体参见这个论文 |
| 索引 | 本地索引 | 本地索引 |
| Join的语言 | lookup操作支持两个collection之间的简单相等join,只支持简单的标量字段。对于数组的字段需要在join之前拆解: 两个collections中的一个不能分片,也就是说不能join大的collection 对简单的不是相等join需要一个独立的管道阶段,也就是说这样的join效率会非常低并且消耗很多资源 类似SQL的LEFT OUTER JOINs,用户必须要加入额外的管道流程来获得INNER JOIN和别的joins | INNER JOIN, LEFT OUTER JOIN, NEST 和UNNEST 操作. 标准的SQL语法 默认支持分片数据库 支持相等的和其它任意的复杂join语法 |
| 查询过程之数据大小 | aggregate()的中间过程的数据大小不能超过100 MiB,需要具体写Query的人使用特殊的标志来允许这个。 | 没有限制,当中间过程的数据(比如哈希表,有序数据)过大,会自动分拆到硬盘上。 |
| 查询过程之JOIN类型 | LEFT OUTER JOIN | INNER JOIN LEFT OUTER JOIN |
| 搜索 | 支持查询中的搜索,使用基于云的Atlas搜索以及基本的B-tree为基础的on-prem搜索 | 解析服务没有内置的搜索,需要使用有FTS的查询服务和查询中搜索相结合。 |
| 支持的查询 | find() 和aggregate() | SELECT 声明(支持SQL 和SQL++) |
| JOIN类型(语言) | $lookup — 这是类似于LEFT OUTER JOIN (不支持数组key的join等等) | INNER JOIN LEFT OUTER JOIN |
| JOIN类型(实现) | 只可以在一个分片和另一个不分片的collection之间进行 只支持嵌套循环(NL)(NL对大的数据的处理性能很差) 中间数据的限制是100MB,用户需要知道数据的大小并且使用不同的选项来允许溢出 | 分片数据的join,所有的数据库都是默认分片的 支持嵌套循环,广播和并行哈希join 支持嵌套循环join和哈希join 默认使用哈希join — 可以满足大规模数据处理 中间数据没有大小限制 |
| 聚集 | 支持通过aggregate()方法的grouping和aggregation操作 | 支持通过GROUP BY和各自的aggregation操作来实现一般的grouping以及aggregation操作,具体见下行的可视化聚集 |
| 可视化聚集函数 (也许是最酷的SQL特性了) | 不支持,用户需要自己写代码来处理。具体可以见这个报告 SQL to NoSQL – 7 Metrics to Compare Query Language | 完全支持 RANK() PERCENT_RANK() DENSERANK() ROW_NUMBER() CUME_DIST() FIRST_VALUE() LAST_VALUE() NTH_VALUE() LAG() LEAD() NTILE() RATIO_TO_REPORT() |
| 多个cluseters之间的数据分析 | 所有的数据分析都是来自于一个单独的MongoDB cluster | 6.5: 所有的数据分析都来自一个单独的Couchbase cluster 6.6: 可以吸收和分析来自多个Couchbase cluster的数据 |
| 外部数据 | 支持S3数据的查询,支持BSON, CSV, TSV Avro和Parquet格式 | 6.6: 支持外部S3的JSON, CSV 以及TSV数据 |
| 外部数据源 | 支持通过JDBC驱动的外部数据源,可以通过聚集管道进行集成,见$sql operator. | 支持上面提到的所有格式 |
| 子查询 | 通过聚集管道的子查询 | 标准的SQL子查询 |
| 查询计划 | $explain | EXPLAIN |
| DataViz | 内置MongoDB的图表 | 没有内置 DataViz |
| 商务智能 | Knowi Tableau 和其它的 ODBC, JDBC 服从BI 引擎. | Knowi Tableau 和其它的 ODBC, JDBC 服从BI 引擎 |
参考文档
- Comparing Two SQL-Based Approaches for Querying JSON: SQL++ and SQL:2016
- SQL to NoSQL – 7 Metrics to Compare Query Language
- Couchbase Analytics: NoETL for Scalable NoSQL Data Analysis
原文地址:
https://dzone.com/articles/analyze-this-mongodb-amp-couchbase-analytics


Recent Comments