Replication lag常见问题分析
我们在《分布式系统之leader-followers Replication深入介绍》中深入介绍了replication了基本实现,本文主要来聊一聊replication lag常见的一些问题。
我们知道在leader-follower这样的系统中,写操作只能到leader,而读操作则可以分布在多个follower上进行。这也就意味着在一个读比较多而写比较少的系统中,我们其实可以把多个读的load分散到follower上,从而达到一个read scaling的结构。这个想法很好,但是问题也很明显,就是事实上follower和leader之间其实并不是同步的,也就是说你从follower上读到的内容和leader上的内容有可能是不同的。当然,我们说这种不同可能只是暂时的,比如说你不再往leader上写,一段时间之后,各个follower中的数据也就一样了。这种现象我们通常称之为最终一致(eventual consistency)。而这个delay的时间我们称之为replication lag。显然我们希望replication lag越小越好。
读你自己的写 (Read your own Writes)
在实际产品中一个比较常见的使用场景就是读你自己写的内容。比如说我们在某一个讨论下面发了一条评论,那么我们肯定希望自己能立即看到这条评论,而通常来说写是通过leader去写,而读则是通过follower来读的(当然现实中这种场景也不一定会去读,比如在前端就直接先把这条评论加进去,但是假如你刷新了,那可能还是需要去follower读),所以这里一个要求就是我能读到我写的内容。
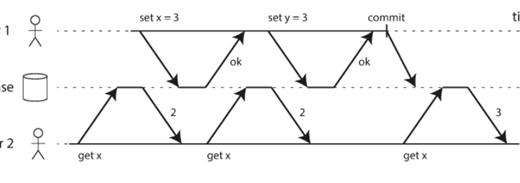
我们来看下面这个图,假如用户在他写了之后立即来读,就会有可能读不到这个刚写的数据,看起来就像这个数据丢失了。
这时候我们就需要一个“写后读一致”(read-after-write consistency)的保证。也就是说用户重新加载页面,能够看到他写的内容,这个保证对别的用户没有影响,就是说别的用户重新加载可能看到的还是旧的内容。那么怎么实现这个效果呢,也很多方法,下面我们来列几个常见的:
- 当读一些用户可能会修改的内容,总是从leader来读。其他的内容还是从follower来读。这就是从business层面来定义哪些从leader读,哪些从follower读。比如说你微信自己的朋友圈,就总是从leader读,假如是别的朋友圈就从follower来读,因为你的朋友圈信息只有你才能修改。
- 但是假如你的使用场景就是很多东西都可以自己修改,假如按照1的方式来设计的话,你就会发现很多东西都需要从leader来读,这样就不能分散读的压力了,这个时候我们可能可以使用一些别的方法,比如看follower和leader之间的lag,假如lag大于一定的阈值就从leader读,否则就还从follower来读等等。
- 客户端可以记一个最近的更新时间,假如replica的更新时间是在这个时间之后的,就可以从follower读,否则就还是从leader来读。但是这种方法也有问题,比如你从多个设备登录了微信,从其中一个设备做了修改,那另外一个设备可能就看不到这个修改了。所以我们需要考虑一下更多的情况。
当然实际应用中情况可能比这种还要复杂,比如你可能需要考虑服务器在数据中心的分布,比如你被route到了数据中心A,而leader则在数据中心B,你又决定要从leader中取数据,该如何来实现,这些都是需要考虑的问题。
单调读(Monotonic reads)
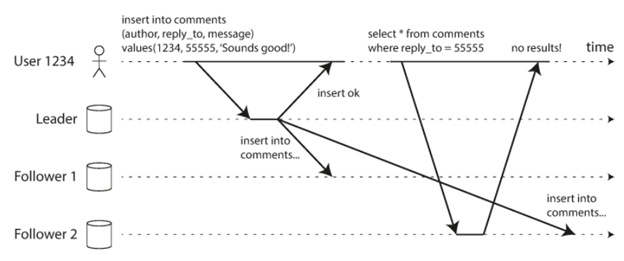
另外一个常见的读的问题,就是有时我们会发现我们会读到以前的值。这是怎么回事呢?我们来看下图,这里有一个更新,就是插入了一个comments,在第一次读的时候,用户访问的是follower1,读的时候这个comments的插入在follower1上已经完成了,所以就读到了这条数据。但是当第二次读的时候,用户访问了follower2,而这个时候其实follwer2的这个插入的更新并没有完成,这个时候读的就是一个以前的值。这就造成了我们之前看到的读到以前值的情况。

而单调读就是保证上述这种情况不会发生。它所保证的就是假如一个用户按顺序读,他读到的值不会变成之前的值。一个常见的来实现这个功能的方法,就是一个用户就一直从某一个follower上读,比如根据用户的user ID来决定他访问的follower。但是假如这个follower出问题了,他不得不redirect到别的follower,还是有可能会遇到类似的问题。
一致前缀读取(Consistent prefix reads)
我们来看这样一个场景:

现在我们假设有第三个人从一个follower上听这个对话,而Poons的replication lag比较大,Cake的replication lag比较小,这个第三个听到的对话可能变成了下面这样:

它具体的时间线可以见下图:

所以这个时候就需要另外一种保证,我们称之为consistent prefix reads。它保证假如有两个写是顺序的,那么任何一个人看到这两个内容也是顺序的。这个问题在有partition(后面文章会具体介绍这个)的时候尤其明显。
所以一个比较常见的解决这个问题的方法,就是有这种顺序的写都写到一个partition下面。但是世事不尽如人意,很多时候我们没法做到这一点,这就衍生了一些新的算法来保证这个,我们在后面的文章中再具体介绍。
总结
本文描述了replication lag常见的问题,当然假如你说lag有个几分钟也没问题,那当然很好,但假如lag存在导致的问题是不能接受的,就像我们上面提到的内容,那么我们就需要深入研究如何来解决他们,我们当然希望使用的database能够帮我们把这些做好,但是每一个database都会有它的trade off,这也是我们为应用选择database时需要考虑的一个因素。



Recent Comments