多index的Partition处理介绍
我们在上文《Partition的基本概念和实现介绍》中主要分析的是key-value格式的数据,也就是说所有的partition都是基于primary key来决定如何route读写请求的。而实际的系统可能不是只有primary key这么简单,它可能会有第二个index,那么如何处理这种有第二个index数据的partition呢?一般来说有两种常见的方法:一种是基于文档的 document-based partition,另外一种是term-base的partition。
Document-based partition
现在我们来假设你在卖二手车,每一辆车都有一个id,然后你的数据开始就是根据这个id来进行partition的。当你开始卖车了,你希望你的用户可以通过品牌和颜色来搜索车辆,所以你把品牌和颜色做成了第二个index。那么数据在各个partition中的存储可能就如下图所示了:
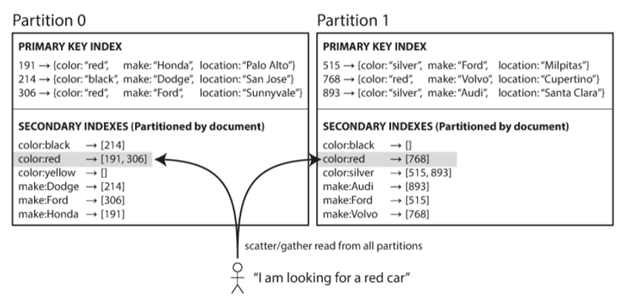
在插入数据的时候,比如说你加入了一个红色的汽车,首先会根据id分到对应的partition中,同时需要更新这个partition中第二个index的文档,比如你加入的是一辆红色honda,它的id是235,那么就需要把这里的color:red插入235的值,同时还要根据你的生产商对应更新make:Honda的值。
我们可以发现,每次其实根据id找到partition之后,所有的更新就都发生在这个partition了,和别的partition没有关系,所以也称这种方法为local index。
细心的你不难发现,这种方法的更新操作很简单。但是读取操作就有点复杂了,比如你想找到所有的红色汽车,你会发现需要找到所有的partition,然后才能得到所有的红色汽车的结果。正是基于这个原因,我们也称这种实现为Scatter/gather。总得来说虽然我们可以平行访问多个partition,但是它的效率其实并不是很高。不过不管怎样,还是有很多数据库使用这个方式,比如MongoDB,Riak,Cassandra等等。
不过换一个角度来想,假如你的primary key选的比较好,比如说根据make来做partition,然后大多数用户可能会有自己心中的车的品牌,一般基于这个品牌再选择颜色,那么这样的存储其实实现的效率还是不错的。
Term-based partition
和上面方法不同的实现,就是我们把第二个index做成一个global的index,然后把这个global index也partition到不同的节点上,而且partition的方法和primary key可能不同,还是上面的例子,我们可以按照下图的方法来组织第二个index的partition:

说白了,就是把第二个index重新partition,比如上面的color按照字母顺序来进行partition,a-r的字母放在了partition0,其他放在partition1。当然我们也可以使用其它方法来进行partition,比如哈希函数等等,不过这个在这里不重要。
我们来看看这种情况下写该怎么做,比如说我们插入了一个银色的Audi,id是893,那么根据id的partition来看,这个数据是保存在partition1中的,所以,在partition1的primary key index中保存了一行数据,然后根据color的字母来看color该更新哪个partition,这里silver是s开头的,所以也保存在Partition1中,所以更新对应的Partition1中的secondary index中的color:silver。然后再看make,这里是Audi,所以开头的字母是A,那么就和之前不一样了,需要更新的就是Partition0中的secondary index了,所以他会更新Partition0中的make:Audi的数值。
我们可以看到这种方法的写操作其实比之前复杂了很多,因为它很有可能就会涉及不同的Partition。那这么做有什么好处呢?答案应该很显然,就是它的读简单了很多了,比如现在我们要搜索所有的红色车辆,就只要找到对应的secondary index所在的Partition(这里就是Partition0)就能找到所有对应的车辆id了,而不需要再去所有partition查询了。
这种实现理论上其实蛮好的,但是现实中一个大的问题就在于一个写操作需要更新多个Partition,既然涉及到多个节点,那么写操作就有可能会有失败和延时,通常来说secondary index的更新是一个异步操作,这也就意味着这里面会有延时,也就是说你刚写入的数据,再立即读就有可能看不到这个数据。比如Amazon的DynamoDB就是这样的实现,在正常情况下,也会有零点几秒的延时,至于极端环境这个延时是没有保证的。
总结
本文总结了多index的partition常见的两种处理方式,各有其优缺点(好吧,要是一方没有缺点,那么另外一种肯定也就不会存在了),希望大家看完能对这两个种方法有个大概的了解。




Recent Comments