Partition的基本概念和实现介绍
我们在之前的文章中讨论了replication的各种实现,我们都知道replication就是把同样的数据在不同的节点上保存副本。这里有一个问题,就是当数据很大的时候,我们需要把数据分成不同的部分进行保存,这个过程就称之为partition,有时也称之为sharding。
通常来说我们需要进行partition的目的并不是说磁盘的空间不够,而是更多地为了scalability,就是说当数据大了之后,query的量过大后,很多时候磁盘的IO等就会成为一个瓶颈,我们就可以把数据分散到不同的磁盘或者不同的节点上,这样就可以分散query的压力,从而提高性能。
Partition和Replication
Partition之后是否就意味着每个磁盘上存储的数据就变小了呢?其实不然,很多时候我们会和replication结合起来,让剩余的磁盘保存别的partition的拷贝,通常情况下会让active的partition分散在不同磁盘或节点上,从而达到balance的目的。
举个leader-follower的例子,它在磁盘和节点上的存储可能如下图所示,理想状况下,我们希望每个节点只有一个leader,其余的是follower(当然出问题的时候,可能就会有多个leader)。
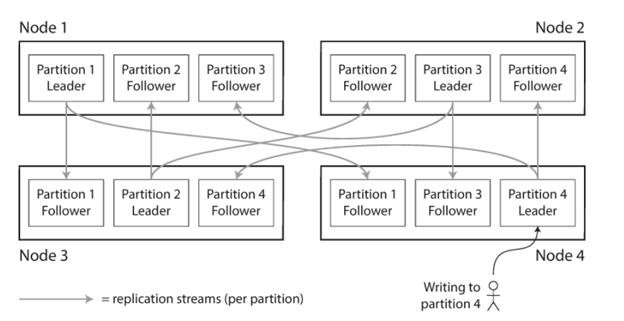
Key-Value数据partition
我们知道partition的目前就是分散访问的压力,那么我们该如何来进行数据的partition呢?你也许会说,我们随机分配就好了啊,随机分配的确有大概率能做到平分访问的负载,但是问题就在于你想访问某一个数据的时候你怎么知道该访问哪个节点呢?你可能仍然需要访问所有的节点,然后才能找到需要的数据,这显然是不合理的。下面我们来看几种常见的partition的方法:
通过key的范围来partition
我们首先会想到的一个partition的方法就是按照某一个key进行排序,然后把某一个段放到一个partition,这样我们查询的时候只要知道这个key就可以知道该去哪里查询数据了,这个方法和图书馆的书架排书是类似的,如下图所示:
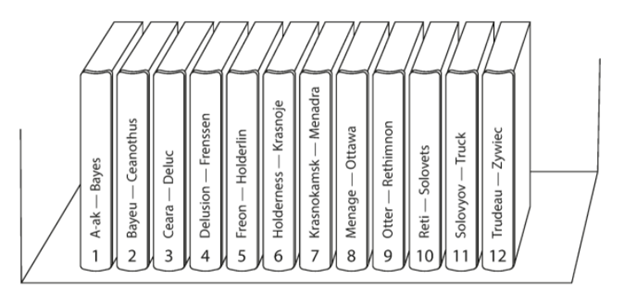
这种实现中,我们并不需要严格按照key进行平均分配,原因很简单,就是一般来说数据也不是按照key来均匀分配的,所以我们可以根据数据的真实情况来分配每个partition的key的范围。假如我们把这些key按照一定顺序排序,那么对于范围的查询就会比较友好,我们可以轻易找到应该访问哪些partition。
这种方法的一个问题就是key的选择,假如你的key没有选择好,可能会导致某些partition的访问非常多,而某些partition的访问则非常少,比如说你选择了时间来做partition,然后你会发现保存最近这段时间的partition的访问可能会比保存之前数据的partition访问量大很多,所以key的选择很重要。
通过key的哈希值来partition
为了避免上面纯粹key带来的问题,我们通常会使用一个key的哈希值来进行partition,就是通过一个哈希函数计算出key相关的值,然后再根据这个哈希值来进行partition。这里的哈希函数就会比较重要了,MongoDB使用的是MD5,Cassandra使用的是Murmur3等等。
当哈希值计算出来之后,就可以根据哈希值来进行partition了,如下图所示:
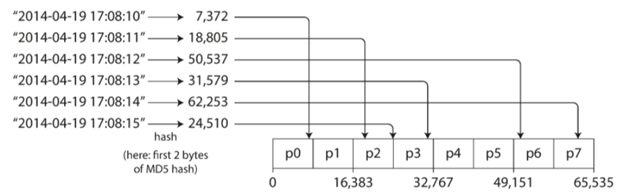
这种方法很好地解决了key的权重问题,但是也带来了新的问题,就是对于key的范围查找很不友好,因为哪怕是一个范围的key它现在也会散列在不同的partition上,从而增加了key的范围查找的难度。
有问题就有解决的方法,有聪明的人说我们可以只把key的前面的部分拿出来做哈希,然后后面的部分可以保证至少这部分范围的key仍然落在同样的partition上。这的确可以解决我们上面提到的范围查找的问题。
热点访问的处理
虽然我们说上面的哈希处理可以有效的处理某个partition访问过多的问题,但事实上并不能完全解决,举个极端的例子,我们所有的访问都是对一个key重复写,那么上面的哈希处理也没有办法很好地护理这种问题。
对于写很热的key,有一个办法就是加一个随机变量到这个key上,从而把对这个key的写分散到不同的partition,不过这样做的问就在于你在读的时候也需要把这些所有的key都读回来。
总结
本文主要介绍了partition的基本概念和key-value形式的几种partition的方法和各自存在的问题。




1 Response
[…] 我们在上文《Partition的基本概念和实现介绍》中主要分析的是key-value格式的数据,也就是说所有的partition都是基于primary key来决定如何route读写请求的。而实际的系统可能不是只有primary key这么简单,它可能会有第二个index,那么如何处理这种有第二个index数据的partition呢?一般来说有两种常见的方法:一种是基于文档的 document-based partition,另外一种是term-base的partition。 […]