分布式系统之怎么都不可靠的网络
当我们聊到分布式系统和单机程序不同之处时第一反应就是多台机器之间的网络问题。多台机器之间的网络连接给我们带来了很多便利,比如我们可以把多个不同地方的机器互联,再也不用担心单台机器带来的性能瓶颈等等。但同时也给我们带来了很多意想不到的问题,本文就来详细介绍为什么我们说网络是不可靠的。
简单Request可能遇到的问题
我们首先来看一下当一个节点发送一个request到另外一个节点,可能会遇到的问题(如下图所示):
- 你的请求可能直接丢失了。(比如发送时网络突然断了)
- 你的请求可能会被堵塞在一个queue中,一段时间之后才会被发送。(比如网络负载很重或者接收端直接过载等)
- 接收端的节点出问题了(crash或者掉电等等)
- 接收端可能出现暂时性的问题,过一段时间才能响应(比如正在做GC等)
- 接收端处理了你的请求,但是response丢了。
- 接收端很快处理了你的请求,但是response回复得很慢。
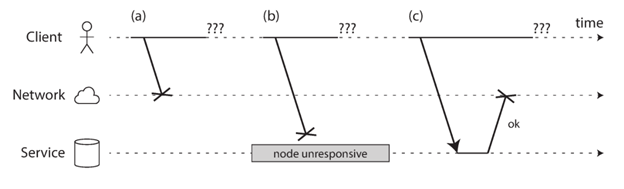
所以从上面的情况来看,一个request出问题,发送端可能压根就不知道发生了什么,是没有发送出去,还是发送出去了接收端没有处理,还是接收端处理了但是response没有能够及时返回。发送端能知道的唯一信息就是一段时间内没有收到response。
正是基于上面的原因,一般来说,这种情况的处理方法就是加一个timeout:一段时间内没有收到response就认为请求出问题了,但是事实上也许接收端还是处理了相关的请求(比如只是response没有能够成功发送回来。)
错误的探测
既然网络是如此地不可靠,那么有很多系统就需要有一个机制来探测网络是否出了问题,比如下面这些场景:
- 一个负载均衡系统需要停止把请求发送给有问题的节点。
- 一个单leader的数据库,假如leader出问题了需要重新做leader的选举。
我们上文已经说了,判断一个节点是否真的工作其实比较难,但是在一些特殊场景下判断一个节点的某一个方面是否工作则是有可能做到的:
- 你可以连接到远端节点,但是没有人在listening,比如说操作系统可以通过返回RST或者FIN包来说明TCP连接已经断了或者拒绝了。
- 一个节点的process crash了,但是整个操作系统还是正常工作的,我们可以主动通过一个script来通知别的节点process crash了,而不需要使用timeout来判断。
- 假如你可以访问数据库网络交换机的管理接口,你就可以通过它来探测硬件层面的连接错误。当然这些的前提是你有访问的权限。
- 假如路由器发现目的IP不能连接,可能会回复你Destination Unreachable的packet。
当然通常来说,我们还是通过心跳机制来进行错误的探测。比如说一段时间没有收到心跳就认为对应的节点有问题了。只是说如何来确定超时是一个值得研究的话题。
超时以及不受控制的延时
假如我们把超时设置得过长,那么在真正出问题到探测到的这段时间内,请求是还会继续发送到这个节点,只是我们会看到很多错误的回复。假如我们把超时设置得很短,那么一个小小的网络波动或者一个负载的波峰都可能导致我们错误地把节点认为是有问题,而这样带来的后果就是把原本属于这个节点的负载转移到了别的节点,这其实也是有问题的(想象极端情况下,很多节点都被认为有问题,从而只有某几个节点在处理请求)– 很容易会产生雪崩效应,比如这几个节点也会因为负载的突然增加而被错误地认为出了问题。
假如我们的网络传输能有一个固定时间的承诺,比如说或每一个包都会在时间d以内完成传输,否则就丢失。然后每个节点都能够在时间r以内完成请求的处理。这样就可以认为我们必然会在时间2d+r内收到response,就可以把超时设置成这个值。
可惜现实中没有这种承诺,下面我们来介绍一下具体的原因:
网络的拥堵和排队
其实就和开车上下班一样,网络包的传输很多时候也会拥堵需要排队:
- 假如有多个源同时给一个目的发送网络包,那么网络switch就需要把它们排好队,然后一个一个发送到目的地,如下图所示。
- 在网络包到达之后,假如所有的CPU都很忙,这个时候操作系统就会把收到网络包排队,直到有空闲的CPU可以处理它们。
- 在一个虚拟机上,有可能CPU会被别的虚拟机在使用,这个时候就会把当前的虚拟机暂停个几十毫秒,而这段时间是不能处理任何网络包的,就只能等待了。
- TCP的流控,这里一个节点会控制网络包的发送速度,也就是说包还没有开始发送就被控制了。
- TCP的重传,就是TCP会在超时没有收到response的情况下自动重传,这也可能会导致延时。
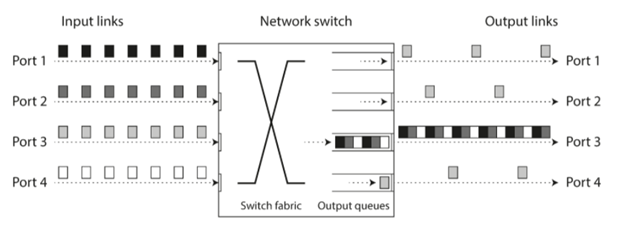
所有我们上面提到的这些都有可能导致各种网络包的延时。在现实情况中,尤其是multi-tenant的数据中心,很多东西都共享的,比如网络,CPU等等,所以他们都很容易被别的传输所影响。
既然有这么多影响因素,我们该怎么选择超时呢?其实我们可以记录真实的数据,然后根据数据来计算期望值,这样就可以基于这个期望值来设置超时的值了。甚至你可以不使用超时,而使用一个分数来判断节点的状况,我们称之为Phi Accrual failure detector. Akka和Cassandra中都使用这个策略。
总结
本文详细介绍了网络传输不可靠的原因和我们一般使用的探测方法。



Recent Comments