分布式文件系统中的MapReduce技术介绍
我们在研究分布式文件系统的实现时,不可避免要讨论MapReduce技术。比较常见的使用这一技术的有HDFS (Hadoop Distributed File System),它是Google文件系统GFS的开源实现。当然很多别的分布式文件系统,比如GlusterFS,QFS(Quantcast File System)以及一些存储服务比如Amazon的S3,Azure Blob Storage以及OpenStack Swift都或多或少有这一技术的影子。本文就来基于HDFS详细介绍一下MapReduce的技术。
分布式文件系统
所谓分布式文件系统,我们可以理解为把文件存储在多个节点中,他们之间通过网络相互连接。从而达到在客户端看起来,这些多个节点就像一台机器一样。为了达到这个效果,HDFS会有一个中心的服务器,我们称之为NameNode,它的作用就是用来知道哪台服务器中存储了哪些文件块,就像大脑一样,我们需要访问某一个文件块的时候,就可以先通过它来确定访问哪一台机器。相应的,在每一台机器上,会运行一个守护进程,它暴露了一个网络服务,这样别的节点就可以通过这个服务访问它上面存储的文件。
和数据库比较类似,为了容错,也会有replication的概念,就是把一个机器上的文件保存多个拷贝在不同的机器上。
MapReduce简介
MapReduce其实说白了是一个编程框架,你可以写相应的代码来处理大的数据集。我们来看这样一个例子:你有一个网站,然后有不同的页面,对应不同的URL,每次有人访问一个页面,就会记录一条记录。 每条记录就是URL和访问的信息,那么现在我们需要对这些记录进行分析,大概的步骤如下:
- 读出记录的文件,把它们分成一条条记录(比如一行表示一条记录)
- 调用mapper函数,从每条记录中提出一个key和value对。比如这里我们需要分析每个URL有多少人访问,可以以URL为key,value设为空即可。
- 根据key来进行排序
- 调用reducer函数来遍历所有的key-value对,并进行聚合,我们的例子中就是把所有相同的URL合并,并计算有多少条(count函数)
假如我们使用MapReduce来实现这些步骤的话,第一步就是输入格式解析,第二步就是map的操作,第四步是reduce的操作,这两步就是你需要实现相关自定义代码的部分。另外第三步的排序不需要额外来做,因为从map出来的输出就是已经排好序的。
那么第二步和第四步的map/reduce是什么意思呢?
- Mapper:这个函数对每一个输入的记录都需要调用一次,它主要用来提取键值对。它不保存任何状态,就是对每一个记录这个操作都是独立的。
- Reducer:处理Mapper出来的输出,对同样key的值进行处理,比如我们上面的提到的计算同样URL的数目等。
分布式执行
MapReduce最大的特点就是可以在不同的机器上并行执行,而且你不需要写什么特殊的逻辑来处理这个并行操作。
我们来看下面这个图所示的例子,它所示的就是Hadoop中的一个MapReduce的job。这里我们把输入进行partition,标志为m1,m2,m3,然后每一个partition都有一个Mapper进行处理。一般来说在决定mapper的运行的时候,会尽量选择靠近相应输入文件的机器,这样一来就可以减少拷贝输入文件的消耗。通常情况下,相应的机器其实并没有运行map的应用程序,所以会把相应的应用程序包拷贝到对应机器,然后在其上运行应用程序,并输出键值对。

在Map处理好了之后,就需要把同样的键值发送给同一个Reduce进行处理(比如图上的r1,r2,r3)等。需要注意的是我们希望进入reduce的数据是按照某种规则排序的,那么这个排序在哪里实现呢?一般来说各个Map会在它本地先进行排序,然后保存一个有序的输出在他们本地,然后通知reduce说我们这边准备好了。Reduce遍历所有的Map,拷贝相关的数据,在这个过程中再进行 一次全局的排序(merge sort),因为每个map都是排好序的,所以在reduce这一端进行排序的消耗其实是相对还蛮小的。我们把这个过程称之为Shuffle,有点confuse,因为洗牌其实是打乱顺序,而这里其实指的是重新排序。最后reduce再根据他自己的逻辑进行处理就可以了。
MapReduce Workflows
其实单个MapReduce能达到的效果是有限的,在现实中会有很多个MapReduce来组成一个链,我们称之为Workflow来处理实际问题。比如我们上面提到的统计每个URL的数目可以用一个MapReduce实现,但假如我们想知道哪些网页是Top 10访问,就需要再加一个MapReduce来实现。
需要注意的是这里的Workflow链和我们通常理解的前面的输出作为后面的输入相比有些不同,它需要把前一个MapReduce的输出保存到一个临时文件中,然后后一个MapReduce需要读这个临时文件作为新的输入。这种设计有好有坏,我们在后面再详细分析。
Reduce的join和Group
从上面的例子中我们很容易看到Reduce部分很多时候做的操作就是Join或者Group,比如计算某个URL的count,说白了就是一个count的Group操作。Reduce和数据库不太一样的是通常来说它没有index来加速这个过程,而且它需要处理的所有的输入数据,因此,一般来说使用的是全表扫描(full table scan)的技术,也就是把所有的输入文件的内容都读出来。我们来看下面这个例子:
同样是统计URL的访问数据,在记录的event中,我们使用的是userID(表示哪一个用户)来记录它的访问信息,我们有另外一张表User database来记录每一个userID的信息,比如哪一年生的,邮箱是什么之类的。这个时候我们需要统计的信息是不同年龄段所喜欢的URL的分布。
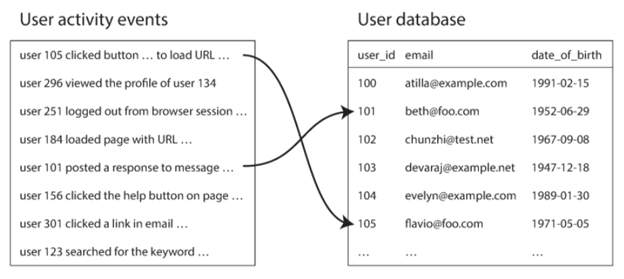
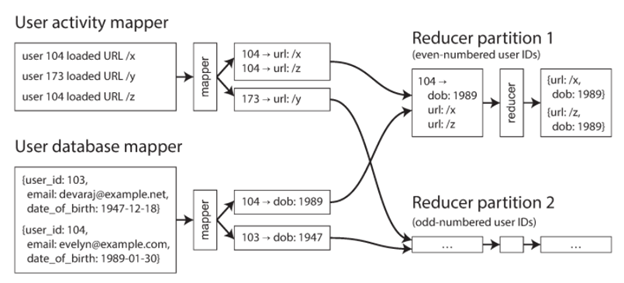
很显然这个时候,我们需要把这两张表进行join,一种简单的方法就是先把User Activity Events和User Database进行join,但是由于他们可能在不同的机器上,远程join的效率就会很低,所以这里我们可以使用MapReduce来同时进行处理。如下图所示:
这里有两个map,一个产生的键值对是userid和URL,一个产生的键值对userid和生日。然后Reducer就可以先处理有序的User database Mapper,然后再处理Activity Mapper(比如按时间排序)。这种技术我们称之为Secondary sort。
这样一来,join的操作就很简单了,Reducer函数对每一个userID调用一次,第一个值就是从User database中拿到的生日,然后把生日保存到一个局部变量,再遍历Activity mapper去查找同样的UserID,这就有了一个viewed-url和viewer-age-in-year的对。有了这些信息之后,后面的MapReduce就可以很方便地计算出我们需要的东西,比如各个年龄段喜欢的URL分布等信息。
Hot Key的处理
我们上面提到的处理中,有一个同样的设置就是把同样的key发送到同一个reducer来进行处理。这种设置有一个潜在的问题,就是假如有某些key非常hot,比如说一些大V的网页会访问得很频繁,那么它的数据记录会很多,这就会导致处理这个key的reducer成为一个瓶颈,因为MapReduce有一个条件就是所有的reducer都结束了才算这个job真的结束。那么一个reducer成为瓶颈就意味着整个job都需要等待它完成。
为了解决这个问题,业界也有很多相应的算法,一个常见的算法就是首先确认哪个key是hot key,然后在做join的时候,让这个key随机发送给多个reducer进行处理。这样就可以分散reducer的处理压力到多个节点,只是有个问题就是后期再进行key的处理的时候,你需要把所有和hot key相关的reduce都再次进行重复发送才行。
为了解决重复发送这个问题,一个新的算法是在hot key选择处理reduce节点的时候不再随机选择,而是根据一定规则进行处理,这样一来的好处就是再进行处理的时候我们可以知道哪些reducer中的hot key是需要的,就不需要每次都进行重复发送了。
总结
至此我们就通过一些实例介绍了MapReduce相关的概念和可能遇到的问题,希望能够对大家理解MapReduce有所帮助。




Recent Comments