ElasticSearch基本概念之Cluster介绍
ElasticSearch是一个基于Apache Lucene的开源搜索引擎。我们都知道Apache Lucene是一个很高效的全文本搜索引擎库,但说到底它还是一个库,所以用起来很不方便,而ElasticSearch就是在其基础上实现的,它屏蔽了Lucene的复杂底层实现,提供了分布式的特性,同时对外也提供了相应的Restful的API。所以,总得来说,ElasticSearch其实上手很容易,本文就从最基本的操作开始来介绍一下ElasticSearch相关的内容。
ElasticSearch的安装
相关的安装很简单,大家可以参见官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.14/install-elasticsearch.html,这里就不详细介绍了。
Cluster的创建
我们都说ElasticSearch是一个分布式的搜索引擎,提到分布式显然离不开Cluster的概念。那么ElasticSearch是如何创建Cluster的呢?
空的Cluster
首先这里有几个概念,第一个就是node,通常来说一个cluster就是由一个或者多个node组成的,这些node具有相同的名字,也就是cluster的名字(Cluster.name)。在cluster中有一个node会被选举成为master,它用来管理整个cluster的改变,比如创建/删除 index,增加或者删除node。任何node都可以选举成为master,当然我们希望任何时候都只有一个master存在。
对用户来说,它是可以和cluster中的任何node来进行交互的,当然也可以和master来交互,被连接的这个node负责到内部相应的node来获取相关的信息或进行相关的操作,并负责返回对应的response给用户。
一个只有一个node的cluster如下图所示,因为只有一个node,所以它也必然会成为master。

增加Index
首先我们来理解一个概念,那就是shard,shard其实就是一个Lucene的instance,我们的文本都存储在shard上,并且在其上进行index。我们可以认为shard其实就是一个数据容器,文本存在它上面,然后它是在cluster中的node上进行分配到的。随着后期数据的增长或者减少,ElasticSearch会自动地在node上迁移shards来保持平衡。但是需要注意的是,应用并不直接和shard通信,而是和index进行通信。
Shared也有primary和replica shard之分,replica shard其实也很好理解,它其实primary的备份,用来提供redundant备份的。当然它也可以服务一些读请求,比如搜索和查询文本。
下面我在上面这个只有一个node的cluster中创建一个称之为blogs的index,这里我们设置三个primary shards,每一个shard都有一个replica shard。

这样之后,整个cluster就如下所示了:

从这个图中,我们可以清楚地看到,node1上有三个primary的shards的,但是因为我们只有一个node,所以其实没有办法做replica的shard,因为primary和replica的shard不能放在同一个node上,否则就达不到我们所说的redundant的作用了。
这种情况下的cluster其实是很脆弱的,也就是说只要这一个node出了问题,我们整个系统就不能工作了。
增加Failover
为了解决我们上文提到的单点失效的问题,我们需要在cluster中增加的node。这个时候增加一个node之后,我们的cluster状况就如下图所示:
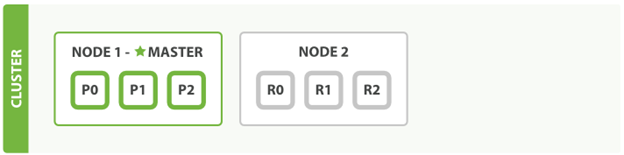
我们可以看到所有的primary shard这个时候都有了一个replica的shard。这也就意味着一个node的失效,我们仍然可以继续工作而不出问题。
当然为了达到primary和replica同步的效果,任何primary的文档的修改,都需要在primary更新之后同步到replica中,当然这里也有异步,同步等多种更新的方式,不同的方式有其优缺点,我们会在后面详细介绍。
水平扩展
有了Failover之后,我们的cluster工作得很好,随着数据量的增加,我们会发现现有的节点可能不能支撑三个shard的流量要求,这个时候就需要进一步扩展,我们可以增加第三个节点,并且重新分配各个shard在节点中的位置。如下图所示:
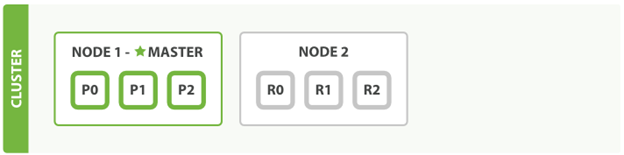
这个例子中,我们分别从node1以及node2中各移出了一个shard放到了node3中,从而达到某种意义上的平衡。这样一来我们就可以更好的平衡各个node的硬件资源了(比如CPU,Memory,网络IO等等)
我们这里的六个Shards其实是由上文创建时候的number_of_replicas和number_of_shareds决定的,假如我们发现六个shards还不能满足要求,其实是可以动态更新这个值的,比如说我们可以replica的数量修改为2,如下所示:

这样一来整个cluster就会有九个shards了,如下所示:
Failover的处理
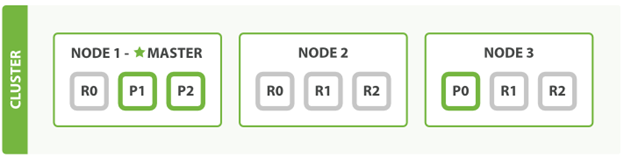
我们之前提到多个node以及replica的存在一个很重要的作用就是为了防止单点的failure,那么假如有node出问题了,会怎么进行处理呢?我们假设上面提到的node1出现了问题。
首先,node1是一个master node,它出问题之后就意味着整个cluster再也没有了master,我们首先要做的就是重新选举一个master出来,我们这里假设node2重新成为了master。
同时node1中有两个primary的shards,分别是P1和P2。Primary shard是非常重要的,必须要存在,否则相应的index就不能工作。所以我们需要在Node2和node3上中重新assign相应的primary shard。这里我们把node2中的shard2变成primary,把node3中的shard1变成primary,所以node1出问题之后整个cluster中的节点就变成了如下图所示的样子。
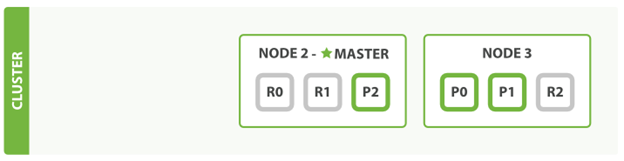
当然当node1重启回来之后,就像新加入 一个node一样,我们还可以恢复到类似之前的分布状态。
Cluster的状态
也许你会问我们有没有办法看到cluster的状态,答案当时是有的。Cluster的健康状态是一个很重要的指标,它有以下三个值:
- Green:所有的primary和replica shard都是active的
- Yellow:所有的primary shards是active的,但是不是所有的replica shard都active
- Red:不是所有的primary shards都active。
你可以通过如下命令来得到对应的状态:

它会输出类似下面这样的结果:

你可以根据这个结果来确定相应的cluster的状态。
总结
至此本文就介绍完成了ElasticSearch中的cluster相关的概念。希望能对你理解ElasticSearch有所帮助。




Recent Comments