Kafka基础介绍之Producer
我们在之前的《Kafka基本架构和概述》中提到了Kafka的几个重要的组成部分,本文就来深入聊一聊其中的Producer的概念。
简介
我们知道要想使用Kafka,其实最开始就是要创建一个Producer来往其中写消息,可以称之为消息源头吧,没有Producer来写,也就谈不上后面的consumer读了。
写消息粗听起来很简单,但是我们仔细思考一下这里就有很多问题需要确认。比如你的应用可以接受某些消息没有成功写进去吗?或者能够接受有重复的消息被写入吗?亦或是你的应用对写入的速度和延时有要求吗?
各种应用显然对我上面提到的问题有不同的答案,比如说一个log系统,丢一条或者少一条数据并不重要,延时一个几十秒甚至几分钟也不是什么大的问题。但假如是一个销售的系统,丢一条或者少一条销售数据可能就不行了。因此对于不同的应用,不同的要求,Kafka的producer可能都需要有不同的设置来进行匹配。
Kafka的Producer的写API其实总体来说还是比较简单的,下图就是一个比较详细的发送数据的流程:
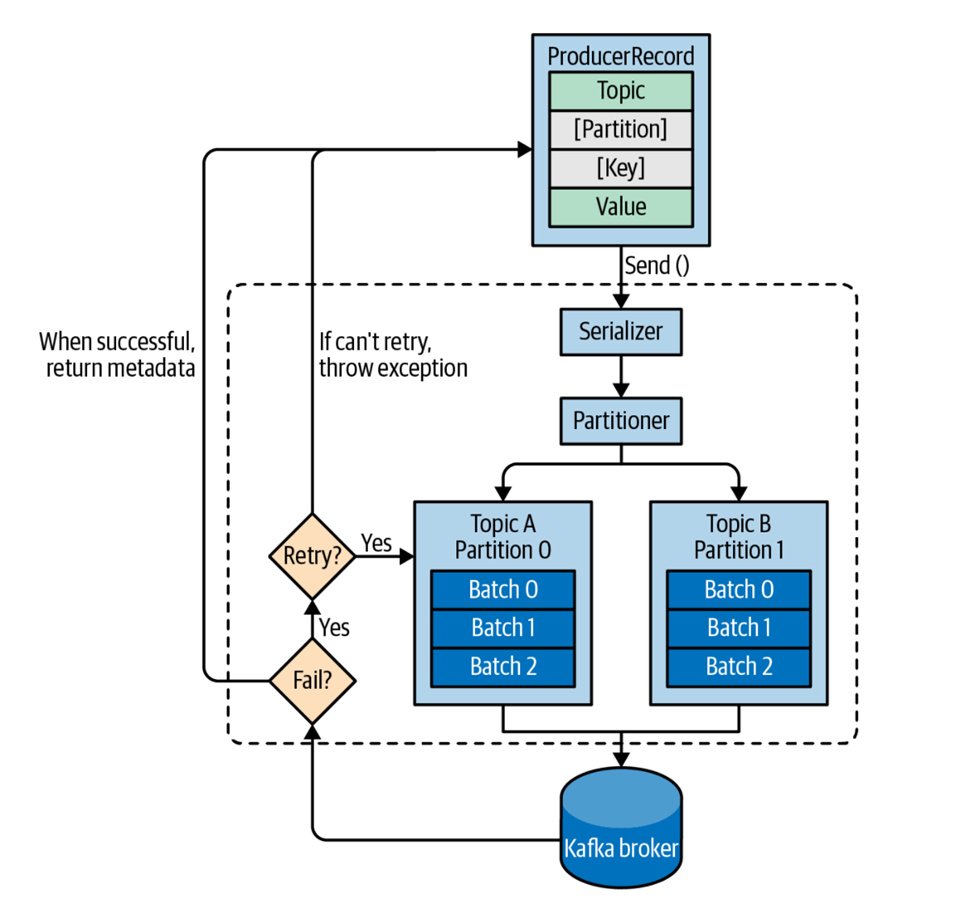
它主要有下面几个步骤:
- 创建ProducerRecord,它主要包含我们想要把数据发送到哪个topic以及发送的数据的值。当然也可以指定别的信息比如key,partition等等。
- 和别的网络call一样,在真正发送的时候还是要先Serialize的。
- 假如我们没有指定partition的话,就会先把数据发送到Partitioner,它会选择一个partition,然后把这个数据加入到那个topic-partition对应的batch list中。
- 会有另外一个thread来专门把这些batch的数据写入到broker中。当成功写入到broker的时候,它会发送一个response给producer。
- 如果broker写入错误,那么这里其实有两个地方可以retry,一个是内部的retry,一个是通知producer端来决定retry。我们后面会详细介绍这两种retry可能会带来的不同效果。
创建Producer
在所有操作的最初当然就是创建producer了,在创建producer的时候需要首先创建一个可以传给producer的property:

这个property有几个部分是必须要设置的:
- Servers:主要就是producer连接的broker列表,没有必要把cluster中所有的broker都列出来,但最好还是至少列两个吧,这样可以防止单点fail。
- Kye/value Serializer:就是用来决定如何serialize数据的。
有了property之后就可以直接传给producer构造函数来创建相关的producer了。所以我们对producer的各种config就是在property中设置的,这里就是最基本的默认设置,我们在本文最后再来介绍一些常见的设置。
发送数据
在producer创建完成之后,我们就可以使用它来进行发送数据了。发送数据有几种方法:
- 发了就忘:说白了就是我只管发送,至于有没有送达以及送达之后有没有什么exception发生一概不管。
- 同步发送:其实在上面的架构介绍中,我们可以发现发送和最终写到broker中并不是同步的,它其实是有一个额外的thread在处理的,所以技术角度来讲,数据的发送都是异步的,但是我们可以在发送函数后面加一个get()函数来等待response从而达到一个类似同步的效果。
- 异步发送:就是直接调用send()函数,当有response的时候再用回调函数来处理。
我们首先来看一个发送的例子,如下所示:
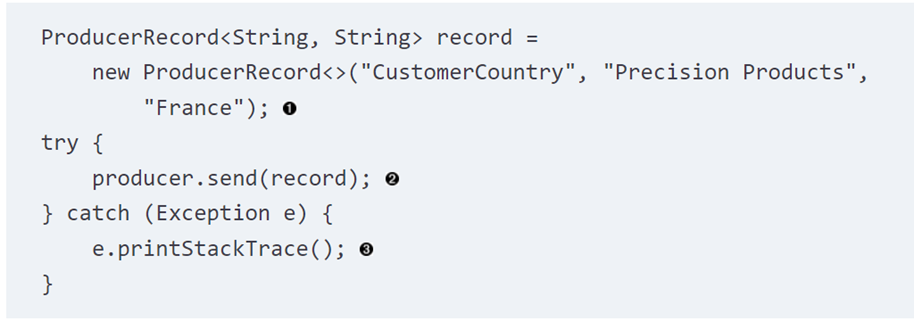
这里我们创建了一个ProducerRecord,然后调用了send()函数。就像我们上面提到的一样,因为到broker的写是一个新的thread,其实这种方法并不知道数据最终有没有写入到broker中,它只能catch前一部分到写到batch之间发生的exception(比如serialize失败等)。
我们这里就可以使用get()方法来进行优化(同步发送),如下所示:
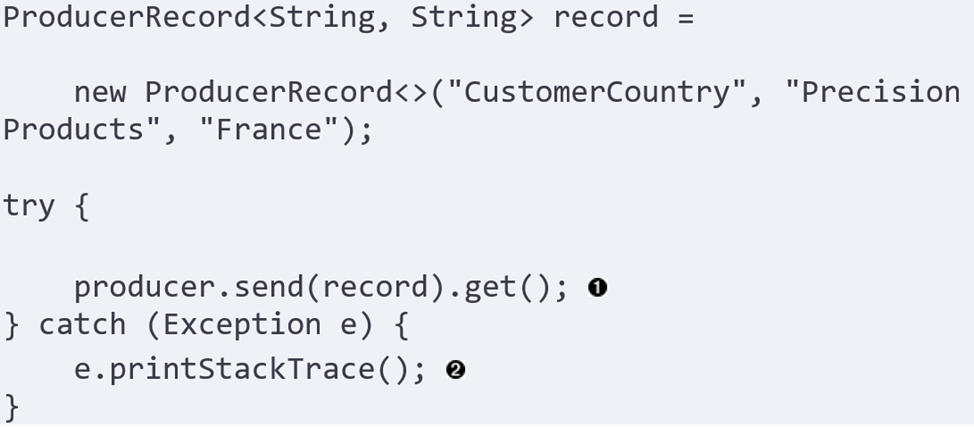
这种方法和上面的差别也很明了,就是在send()之后加了一个get()。这个get()它会等待Kafka的reply,这样一来假如在最终发送到broker的过程中出现了问题,我们也可以收到exception。我们上文提到的retry的逻辑也是可以在这里处理的,当有retriable的error发生的时候(比如“not leader for partition”等),我们可以决定是否要进行retry。
当然我们也可以使用异步发送,就不会一直堵塞在这边等待response了,相关的代码如下所示:
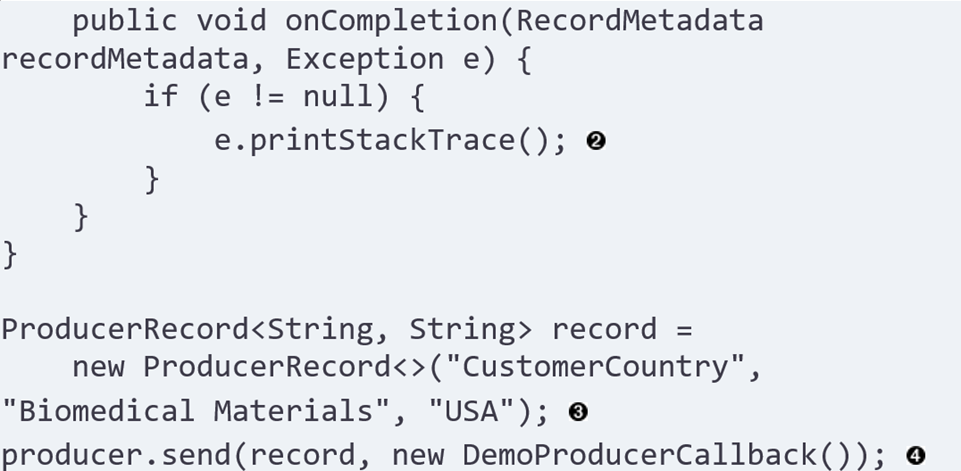
整个代码也很明了,就是创建了一个回调函数,把它作为send的参数进行调用。这样一来在成功(失败)写入到broker之后,这个回调函数就会被调用了。
Producer的设置
我们在上面就简单介绍了Producer的创建和数据的发送,也许你已经注意到我们在创建producer的property的时候使用的就是默认的设置,而事实上还有一些比较有趣的设置我们可以使用:
Client.id
这个其实是broker用来区分数据是由哪个应用程序发送过来的,它是一个string,设置好这个,对我们的debug会很有好处,因为很容易就可以区分问题出在哪个client端。
Acks
这是一个很重要的参数。它是用来设置我们在成功写入几个partition的replication之后才认为这个写是成功的,它有下面这几个值可以设置:
- Acks=0:producer不需要等待任何从broker的reply就认为写成功了。其实就是不关心真的是否写成功。
- Acks=1:这种设置情况下就只关心在leader上的写有没有成功,不关心是否有replication,问题就是假如leader写成功了,也返回了成功给client端,但是leader突然crash了,这个时候leader就转移到一个replication上了,但是这个replication可能还没有刚刚完成的写,也就导致了client认为写成功了,但事实上数据还是丢失的情况发生。
- Acks=all:只有所有的in-sync replication都成功写入之后,才会返回成功的response,所以这种写是最安全的,即使leader发生了变化,因为新的leader上已经有了相关的数据,因此不用担心数据丢失的问题,但是显然它的延时也是最大的。
超时时间
在了解各种超时的参数之前,我们先来看看一个producer的写究竟包含了哪些时间因素,如下图所示:
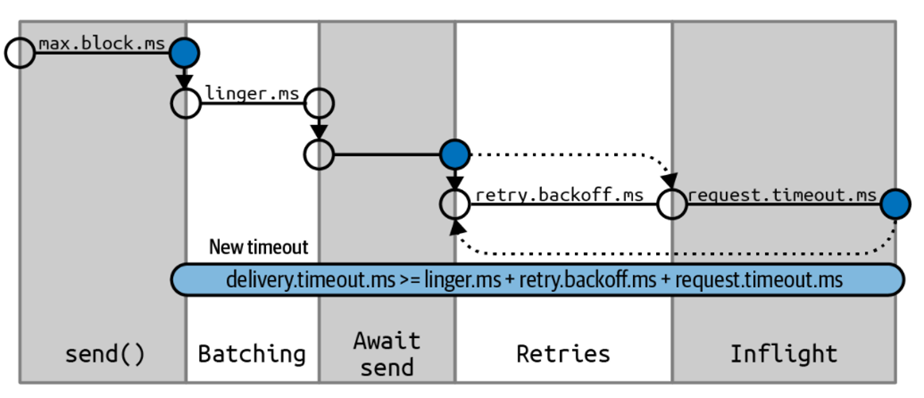
Max.block.ms:这个其实就是调用send()函数所能block的最大时间,其实就是send buffer的block时间。
Linger.ms: 这个是batch等待的时间,就是发送一个batch之前,我们一共等待的时间。
Batch.size: batch发送的时间还由这个值控制,就是当batch的大小超过这个大小的时候就会做一个batch的发送。
Max.in.flight.request.per.connection: 这个用来控制一个producer在没有收到response的情况下最多能发送多少batch数据给server。
Request.timeout.ms: 这个时间就是包含每一个reply的等待时间,它不包含retry的时间。
Retries和retry.backoff.ms:这个就是当写入失败的时候,retry的次数和每次retry之间的间隔时间,默认是100ms。
Delivery.timeout.ms:这个超时包含了从数据准备好了被发送,到最后数据成功写入broker的返回之间的时间,假如中间写入失败,它还包含了重试的时间。因此假如我们还在retry,然后超时了,我们上面的async方式下的回调函数就会被调用(with exception)。
总结
本文简单把producer相关的创建和发送介绍完成了,最后简单介绍了一下producer property相关的设置,希望对大家有所帮助。




Recent Comments