Kafka进阶之物理存储
我们都知道Kafka数据是可以持久化保存在磁盘上的,它在磁盘上最基本的存储单元是一个partition的replica,我们可以通过log.dirs参数来决定partition保存的文件目录,本文就来详细和大家聊聊Kafka是怎样使用这个目录保存文件的。
Partition的分配
当我们创建一个topic的时候,Kafka首先要做的事情就是如何为对应的partition分配空间。我们假设你的topic有10个partitions,每个partition有3个replication,然后总共有6个brokers。这也就意味着我们需要在6个brokers中申请30个partition replicas。一般来说,我们会遵循下面这些规则来进行分配:
- 让replica在broker中尽可能均匀地分布,比如我们的例子会希望每个broker有5个replica。
- 对于每个partition来说,希望每个replica是在不同的broker上,这个也很好理解,我们在《Kafka进阶之Replication》中解释过replica的一个作用就是用来做错误备份的,放在同一个broker上就失去了其原有的意义。
- 假如broker有rack的info,那么尽量让同一个partition的不同replica分布在不同的rack上,这样做其实也是为了防止rack level的灾难影响Kafka的运行。
有了这些规则之后,我们来看上面这个例子该怎么处理,我们先不考虑rack的情况。首先随机选择一个broker,比如说broker4,然后把partition 0的leader放在它上面,然后partition 1的leader就可以放到它后面一个broker,比如broker 5,partition 2的leader就可以放到broker 0 (一共就6个brokers:0-5),以此类推。对于follower的replica,则可以直接放到leader所在broker的后面一个即可,比如partition 0的follower 1可以放到broker 5 (leader在broker4),follower2可以放到broker0,然后对于parition1也可以做类似的事情。
有了Rack之后该如何处理呢?其实也比较方便,我们上面就是直接把broker按照0到5的顺序进行排列,然后依次使用的,引入了Rack之后则需要进行一些额外的处理,比如说broker0,1是在Rack1上面,broker2,3是在Rack2上面,broker4,5是在Rack3上面,那我们不再使用broker 0,1,2,3,4,5这个顺序进行分配,而是变成broker0,2,4,1,3,5.也就是说每个broker和前面的broker都不在一个rack上进行排序,这样一来,当我们按照上面的顺序来进行分配partition和replica的时候就可以尽量让他们分布在不同的Rack上面了。按照我们的理论如下图所示:
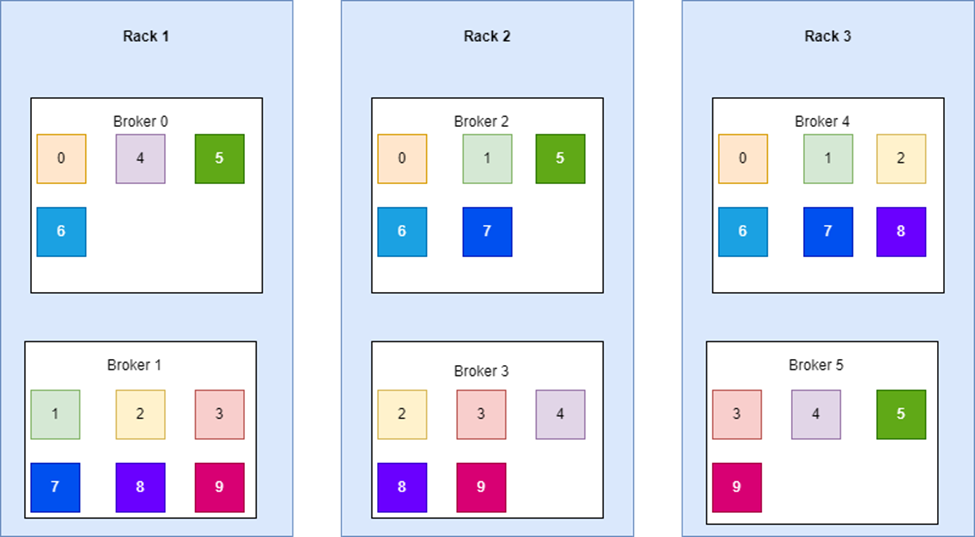
当然在我们的例子中并没有能够完美分配,有几个broker上面并没有5个replica(一般来说多一个少一个是可以接受的),大家也可以思考一下假如就是这种情况,我们可以怎么优化,让每个broker都是完美的5个replica。
在为每个replica分配了broker之后,下面一步就是为他们分配目录,这个分配的规则也很简单,就是我们按照每个目录上已有的partition数目来进行排序,新的partition分配给partition最少的目录,这样就可以做到一个平衡了。
文件管理
我们一直说Kafka会持久化数据到磁盘,但是它并不会一直保存数据,一般来说一段时间之后或者一定大小之后就会把旧的数据删除了,那这个删除的过程是如何实现的呢?
实现的方法其实并没有什么新意,也还是分成segment来处理,就是partition的数据每次都写到segment里面,然后当这个segment达到一定大小(默认为1GB)或者一定时间(默认一个星期),就会把这个segment关了,重新创建一个新的segment来继续写。正在写的segment我们认为是active的segment,这个segment是不能delete的,然后我们再来检查非active的segment是否符合delete的要求,如果符合再进行delete。
每个segment其实说白了就是一个磁盘上的文件,一般来说我们会直接根据producer发送的message的格式来进行存储,这样就可以实现我们之前说的zero-copy的优化。不过这种格式的存储也会出现一些问题,就是我们需要额外处理message格式中途改变的问题。
在我们引入了segment之后,一个查询的问题就随之出现了,就是当consumer来查询某个offset开始的message的时候,比如说consumer要查询offset 100开始的1MB数据,我们怎么才能知道offset 100是在哪个segment呢?这里很容易就可以想到我们需要一个index来快速从offset定位到segment。所以这里Kafka会维护一个index,它映射了offset到segment文件以及文件内部的位置。当然offset的查询只是其中一种场景,有时我们还需要基于timestamp的查询(比如一些failover的场景),所以Kafka还维护了一个关于timestamp到offset的第二个index。另外我们前面也提到了segment会被删除,所以index其实也会按照segment来进行区分,一个segment被删除之后,我们可以迅速删除相应的旧的index。
Segment的compact
除了我们上面提到的删除操作,Kafka其实还有一种使用场景:它只关心最新的状态,不关心中间的变化过程,这种情况下,其实没必要进行删除,我们可以使用compact来进行处理。所以我们可以设置Kafka的retention policy为delete(就是前面提到的一定时间之前的数据删除)或者compact(就是这里要说的只保存key的最新value)。当然两者也可以结合起来,比如某个时间之前的数据我们一定会删除,哪怕它包含了某个key的最新值(这个key只在某个时间之前才被update过),这也算是一种防止只compact的设置导致文件过大情况发生的处理方法。
那具体来说是如何compact的呢?首先每个event log都会被分成两个部分,一个是clean的部分,这个部分就是已经完成了compact的部分,另一个是Dirty的部分,就是在上次compact之后写入的数据,如下图所示:
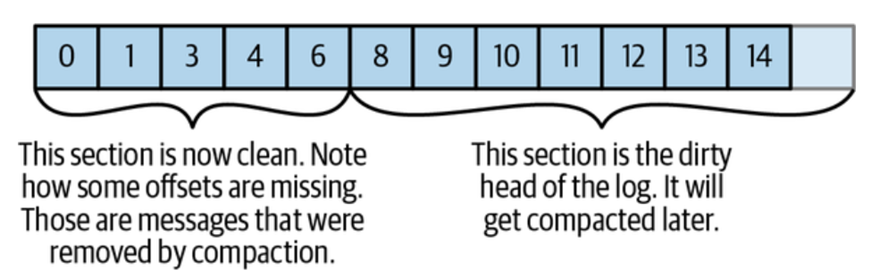
当compact开始的时候,有一个clean的thread,它会把所有的dirty的部分都读到一个内存map中,map的entry就是一个16 byte的message key的hash和一个8 byte的offset(同样的key取最新的),所以每个entry就是24byte。这样一来,就算是一个1GB的segment,每个message的大小是1KB,那这个map最多也只要24MB,更何况如果有重复的key,这个大小会更小。所以说白了就是这个map就是dirty部分的key和最新offset的mapping。
有了这个map之后,就可以来和clean部分结合起来,我们先读入clean的section,然后一个一个check 这个offset在上面build出来的map中是否存在,不存在就直接读clean部分的内容,拷贝到新的segment即可。假如存在这个key,就使用dirty中的最新的内容。这样一来我们就可以最终build出来一个新的clean的segment。在clean的section中,每个key就只有一个value,如下所示。
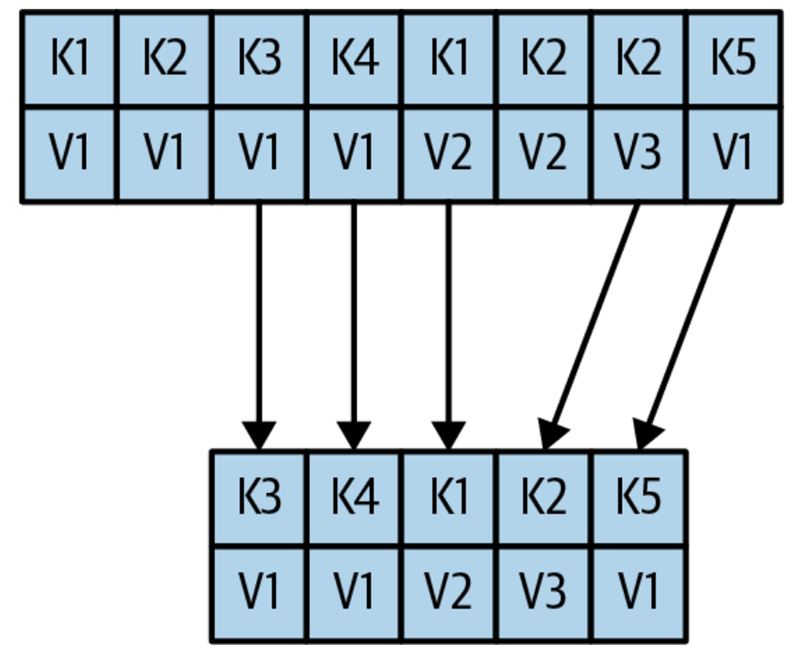
这个时候,你也许会想问,我们总是保存最新的key、value,假如我想删除一个key该怎么办呢?其实也简单,就是produce一个value为null的key/value对,当Kafka收到这样的key/value对的时候,它就会把这种key单独进行处理,并不会立即删除(删除了你就不知道这个key是被删除了还是压根没产生过),而是保存一段时间,然后再进行删除处理。
总结
本文基本上就把Kafka相关的存储部分介绍完毕了,大家有任何问题都欢迎留言讨论。




Recent Comments