2021 Roblox宕机事件回顾
Roblox在2022年一月二十号针对他们2021年十月份的一次宕机事件进行了回顾,很巧的是这次Roblox宕机的模块和笔者目前负责的模块实现的功能几乎是一模一样的,中国有句古话是“以史为鉴,可以知兴替”,我想这也是Roblox最终决定公布他们这一事件回顾的原因之一,希望各位读者和笔者一样都能够从这次宕机事件中学习到一些东西。
事情回顾
这次的宕机事件发生在2021年10月28日,整个宕机事件持续了73个小时,一直到10月31日才算完全恢复。这么长时间的宕机事件其实在业界也算比较罕见。根据官方记载,目前每日有近五千万用户使用Roblox,所以整个事件影响的规模还是蛮大的。所幸的是整个事件并没有造成数据的丢失,也没有造成任何安全性相关的隐患。
基础架构介绍
在了解事情发生的情况和原因之前,我们需要了解一下涉及到的相关模块的功能和架构。Roblox并没有使用云方案,而是有自己的数据中心,他们自己维护自己的各种硬件,包括计算、存储、网络等等。大概有18,000台左右的服务器以及170,000 container。
那么他们是如何进行管理这些服务器的呢?他们使用的是一个称之为“HashiStack”的技术,这个技术涉及到了下面几个关键部分:Nomad,Consul以及Vault。
Nomad主要是用来scheduling work的。就是用来决定哪个container在哪个节点上面运行以及可以通过哪个端口来进行访问,同时它也会检测container的健康状况。所有这些数据都会放到一个称之为service registry的地方,这个service registry说白了就是一个数据库,保存了IP:Port的组合。Roblox的各个service就是通过这个service registry来判断应该和哪个端口通信的,类似一个服务发现的功能。
Consul是一个cluster,由一系列节点组成,这些节点有两种类型,一个是参加leader选举的我们称之为voters(Robox设置的节点数目是5个),另外一个系列是不参加选举,但是仍然会replicate相关的数据,它主要的功能是分散读的压力(节点数据也是5个)。这个cluster本身是基于Raft来实现的,我们之前在讨论活动中也介绍过Raft,相信大家对它也不陌生。整个Consul从另外一个角度来讲是一个KV store。
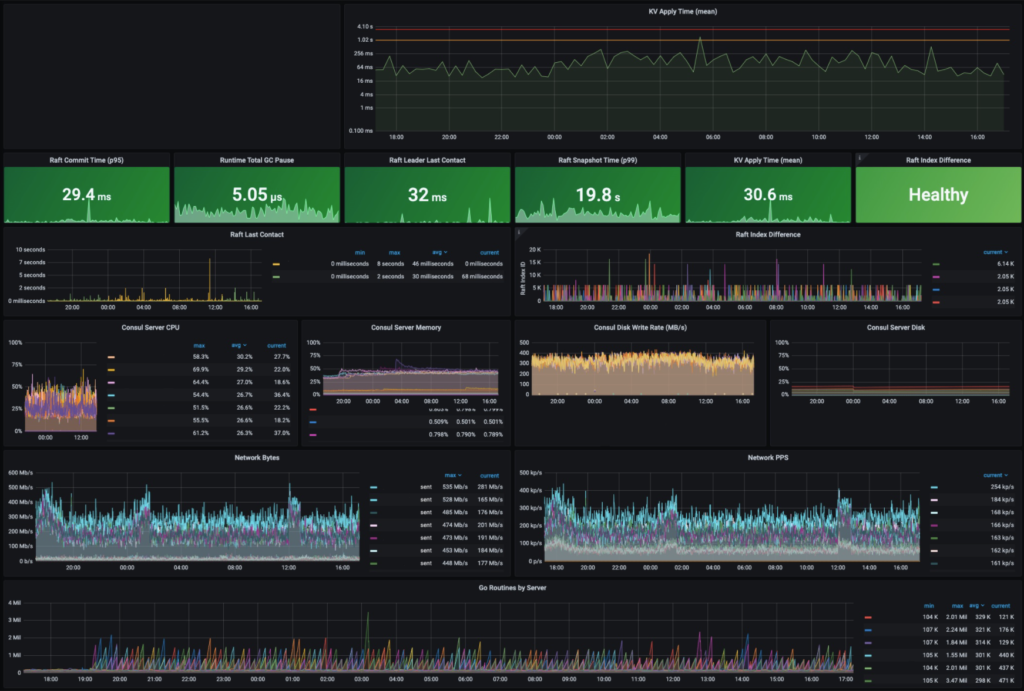
下面这张图展示了一些正常情况下的数据,比如说KV写的延时是30.6ms,通常认为低于300ms都是正常的。Leader上次和别的server连接的时间是32ms,这个时间是非常短的。
问题分析过程
在10/28的下午,Roblox的监测系统发现Consul中的某一个server的CPU使用率突然飙升,所以他们的Oncall就开始进行调查。当时Roblox团队随后发现整个KV store的写latency突然增加,P50增加到了2s(我们上面说过超过300ms就认为不正常了),我们知道在Raft这样的系统中,单个节点出了问题,整个系统还是可以工作的,但是单个节点突然变慢,整体的性能也会被拖慢(我怀疑可能和选择的写策略—写几个节点才算成功–有关,他们文章没有详细说明)。
有了这样的认知之后,整个engineer团队准备做的第一件事就是把那个CPU飙升的server拿替换了,这样可以排除单个server的硬件带来的影响。然而很不幸,即使这个server换成了一个新的server,整体性能并没有任何改善,反而在16:35的时候发现在线的用户突然降到平时的一半,如下图所示。这说明这个性能问题已经影响到了用户的正常使用。
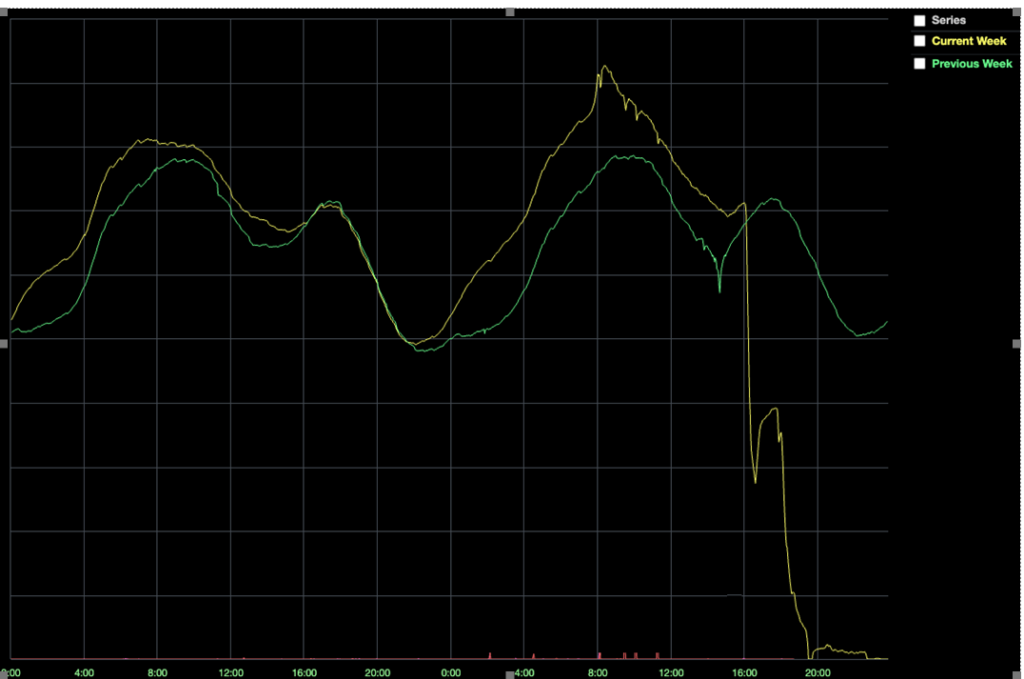
随着时间的推移,越来越多的用户收到了影响,直至近乎所有的用户都被迫下线。这是为什么呢?原因也很简单,Roblox的service之间的通信都需要通过Consul来获取我们前面提到的IP/Port信息,当Consul发生问题的时候,所有依赖于它的service都没法正常工作了。
这个时候整个Engineer团队还在思考究竟有什么会导致server的CPU如此高,已经排除了硬件问题的可能,那么有另外一种可能,就是traffic突然增大了,导致了现有的server无法承担这么多的traffic,从而CPU飙高。(我比较怀疑他们是否有对应的metric来监测traffic的数量,理论上是需要有这样的metric的,这样我们才能有针对的进行throttling,但看起来他们是猜测的—好吧,我也是猜测他们是猜测的,哈哈)
当他们有了这样的猜测之后,就做了第二次尝试,也就是把所有的Consul节点都换成更加强力的server,新的server有128个核(相对于原来的2倍),换了更快的SSD硬盘。19:00的时候,大部分节点都替换完成,但是很不幸,整个写的P50的latency还是2秒左右,和我们期待的低于300ms有很大的差距。
这个时候整个团队就在猜想是不是有什么奇怪的状态或者config导致了Consul出现问题,于是决定使用一个问题发生前的snapshot来reset整个consul(因为Consul其实存储的是一些metadata,所以不会有数据的丢失),当然可能会有少量config数据的丢失,但是还是可以接受的。当时他们还有一个担心,就是Consul其实被很多内部service在不停访问(外部访问已经停止了),也比较担心说一reset就被这些service又不停读写,然后瞬间进入到一个坏的状态,所以他们把这些Consul的ip访问block了,这样就可以保证是从一个reset的状态来慢慢测试。
果然在整个Consul reset之后,所有的性能都很好,岁月静好,所以他们开始把ip访问的block去除了,很不幸性能很快就变坏了,瞬间就恢复到了之前的2s的latency。这个时候已经是4:00了,距离问题的发生已经过去了超过14小时。
此时已经排除了硬件问题,也排除了外部traffic的影响,但是内部有几百个service在使用它,所以他们决定把内部这几百个service block一部分,只enable另外一小部分,看看会不会有问题,假如这样还有问题的话,说明小部分的service traffic就可能导致问题的出现,那就不是high load的traffic导致问题,而是Consul内部系统可能有了问题,这次实验的结果不错,和预期有所符合,就是即使只enable少部分的service(traffic明显低于平时)的情况下,一段时间之后Consul还是出现了问题。
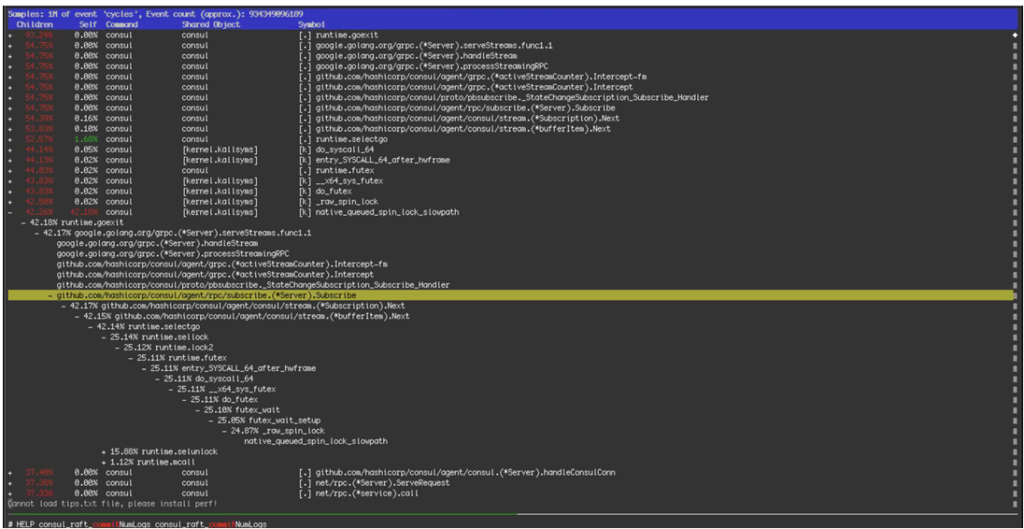
有了上面的实验之后,整个团队开始怀疑Consul本身的逻辑出问题了,所以他们开始分析Consul的内部log(如下图所示),发现写有时会被长时间block,当时有一个理论是说这个写的block有可能是由于之前我们把硬件从64核的CPU升级到128核导致的,所以他们决定恢复硬件到出问题前的64核机器上,其实可以想象,换回去之后问题还是存在的。
当时发现的一致被kernel spin lock影响图:
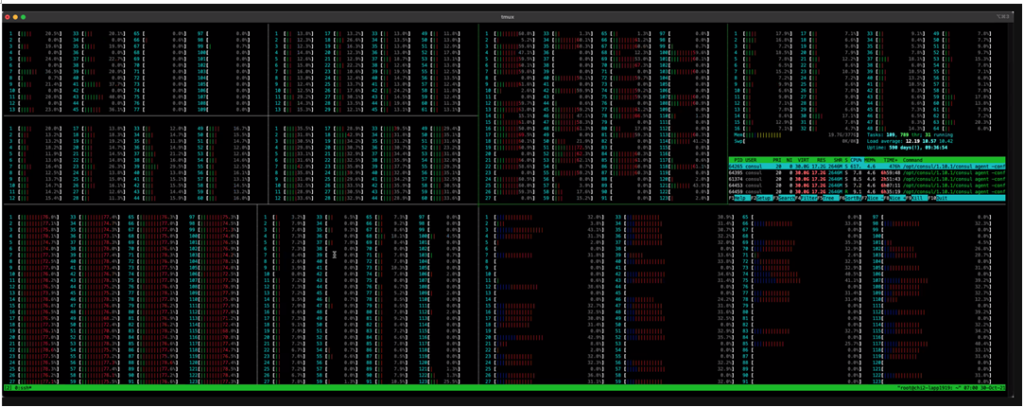
128核上的CPU使用率:
Root Cause
时间回到几个月前,Roblox开发了一个新的consul streaming的feature,这个feature主要目的是减少Consul的CPU和网络使用率。这个feature的测试过程其实很小心,开始只是在一些service上enable,运行并没有问题,进而在更多的service上面enable,这个过程持续了几个月,一切都很好。十月27号也就是问题发生的前一天,他们在一个新的service上也enable了这个feature, 这个service主要是负责traffic routing的。在最开始的一天,它运行得很好,但是一天之后就出现了上面提到的问题,所以他们紧急把这个feature在所有的service上都全部disable,结果Consul KV果然恢复正常了,latency降到了300ms以下。这个时候是十月三十号的15:51。
那么最终是什么导致了这个feature有问题呢?从技术角度来讲,它是因为使用了比较少的同步控制元素(Go Channels),在load比较高,尤其是读写load都比较高的时候,因为设计的缺陷,会在同一个go channel上堵塞,从而影响写的效率。而128核的CPU,因为采用了dual socket架构以及NUMA的内存模型,会让这个问题更加严重。
然而很快团队就发现了新的问题,就是因为Consul会有一个leader重新选举的过程(leader改变这件事很常见),但是有些leader哪怕在feature disable的情况下,也还是很慢,而另外一些leader则性能比较正常。这个时候没有太多的时间来debug为什么某些server成为leader会变慢,所以他们决定把那些慢的leader从leader candidate中去除了,就是不让他们成为leader来先规避这个问题。
那么为什么有些server成为leader之后会变慢呢?这个问题在后期也找到了原因,因为Consul其实使用了BoltDB来保存Raft的log,为了防止log过大,他们每过一段时间就会做一个snapshot,这样就可以删除之前的log,但是在BoltDB的design中,哪怕就的log entry被删除了,它使用的磁盘空间并没有回收,只是会标致成free,然后可以被继续使用,他们使用了Freelist来track有哪些空间是被标致的。通常来说更新freelist并不会影响性能,但是因为Roblox的load比较大,使得这个过程变成了一个性能的瓶颈(主要还是大量的free space导致每次写入都需要更新freelist)。
至此,从出问题到现在已经54个小时了。现在Consul终于稳定运行没有latency的问题了,是时候把外部的服务来进行恢复了,Roblox使用的是微服务的架构,总的来说就是各种服务,然后下面有cache层,再下面就是数据库。数据库的数据没有丢失,但是整个cache层已经完全不能用了,而这些cache层通常来说handle了1B的QPS。不过因为cache层有保存transient数据到下面的数据库,所以最简单的解决方法就是重新deploy来进行恢复。当然在重新deploy cache层的时候也遇到了一些新的问题,不过好在团队都解决了,终于在31号的早上5:00,距离出问题61小时后,Consul和cache层都恢复正常了。
下面一步就是逐步重启上层的所有service,这一步没有什么问题,从5:00到10:00,所有的service都重启成功,可以恢复给终端用户使用了。不过因为因为整个cache layer还是cold cache以及也不是很确定问题是不是真的解决了,还是通过DNS来逐步控制用户的使用量,防止出现雪崩的现象。随着时间的推移,终于在周末的16:45分彻底恢复了正常,整个宕机事件持续73个小时。
总结
这次Roblox的长时间宕机问题说白了还是Consul是一个中心点,而它本身是一个单点failure的系统,这个问题在很多设计架构中也很常见,只是说这次没有能够很快定位到问题发生在Consul上而已,当然有很多公司会有一个备份的不同架构来做redundant保证这种中心架构即使本身出问题也能继续工作,当然相对来讲维护工作就成倍增加,不过Roblox后期引入了Consul的sharding是一个很不错的想法,这样即使一部分出问题也不至于导致整个系统瘫痪。希望这篇文章能给使用类似系统的同学一些预警和帮助。



Recent Comments