Reddit.com的架构演进
Neil Williams在2017年的QCon SF上介绍了Reddit的架构演进,笔者觉得有很多值得借鉴的地方,因此把相关内容进行了整理供大家参考。
Reddit简介
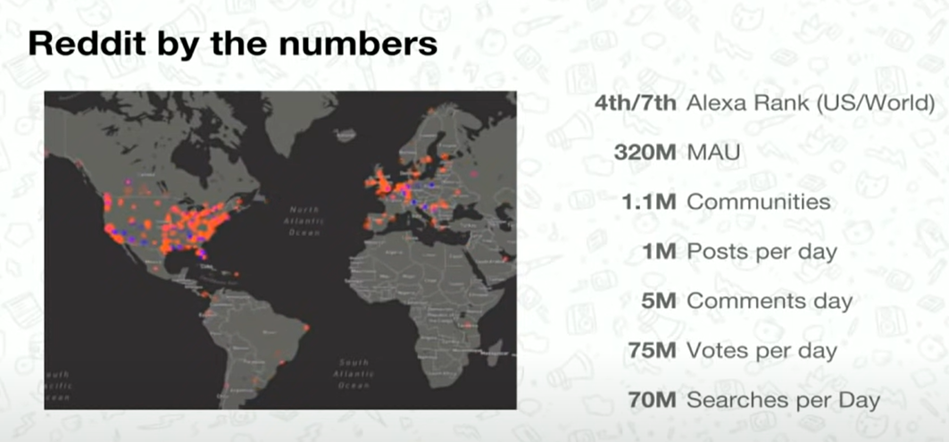
Reddit是一个内容的分享平台,用户通过点赞或踩来进行投票,获赞越多的帖子就会排得越上面。有人开玩笑说它就是美国版的天涯+贴吧。在2017年的时候,它的用户数据如下图所示,大概每天有一百万的post,五百万的评论,7500万的Votes,所以数据量还是很大的。
整体架构
我们先来看看整个Reddit的架构图是怎么样的,它的整体架构如下图所示:
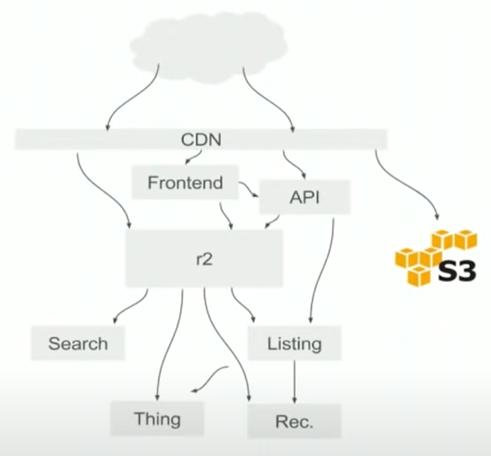
这里有下面几个主要的组成部分:
- CDN: 可以理解是对不同Request进行分发的模块,它会根据domain,path,cookie等内容来决定把请求分发到哪个stack。
- Frontend:基于Node.js开发的前端应用,包含client和server端的代码,它会和API层以及r2进行交互。
- R2: 在早期开发Reddit的时候,它是一个Monolith的架构,现在有一些功能被从中提出来放到整个架构的各个部分(API, Search,Thing, Listing, Rec等),而剩下来的都还在原有的这个Monolith模块中,称之为r2.
R2其实包含了比较多的内容,我们可以稍微deep进去看一下看看r2都由哪些部分组成,如下图所示:
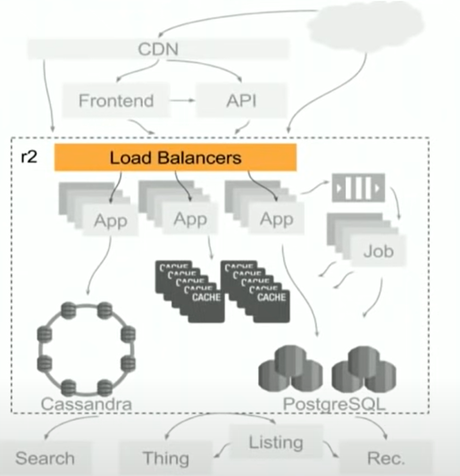
因为r2本身是一个monolith的架构,所以它会把同样的代码部署到不同的server上,虽然代码相同,但是每个server可能只执行某一些功能:
- Load Balancers:这里的负载均衡使用的是HA Proxy,这里会根据请求的path来分发到不同的APP pool,这样也从某一个方面来讲把不同path的负载进行了隔离,减少了相互之间的影响。
- 有一些很耗时的操作是通过Queue来进行处理的,比如用户进行了vote,需要一些job来对这些vote进行处理,就会把它加入到queue(使用的是RabbitMQ)中,然后再通过job进行处理。
- 当然还包括Cache和PostgreSQL层,主要是为包括link,comments等等内容的访问服务的。
- Cassandra是后来引入的,有很多新的feature都是基于它开发的,比如我们后面提到的Cache的固化就是存在这里的。
Listing
除了上面介绍的几个模块,我们来具体看看另外几个模块是干什么的,先来看看Listing。它可以说是整个Reddit最基本的部分了,就是我们在首页看到的那个按照一定顺序排列的list:
最粗略的是实现方式就是使用一个SELECT语句从数据库中查询出一个ORDER BY某种标准的结果。显然不可能每个人访问都进行一次这样的查询,效率会非常低。Reddit当时的做法是第一次是一个SELECT,然后就会把这个结果(ID list)保存到Cache中,然后可以根据这些ID快速找到对应的内容。
然而这种方法的问题就在于这个list是动态变化的,比如说我们list是按照点赞的多少进行排序的,每次点赞都有可能导致这个list发生变化,从而导致Cache中的数据不再正确,那Reddit是如何解决这个问题的呢,它们把点赞的数目也加到了Cache中,这样在处理的点赞的job执行时,也会同步针对这个list在cache中重新排队,如下所示:

这个例子中,开始的时候id=125有8个点赞,排在第三位。这时候有一个新的点赞过来,点赞数目就变成了9个,它就会重新排到了第二位。从技术的角度来说,就是在点赞的job处理中,会首先读取当前cache中的内容,然后根据点赞的结果修改这个内容,然后再写到cache中。是不是发现这种做法已经不能再简单称之为Cache了,准确说已经是某种类似数据库的存储了。另外这里他们为了防止一些冲突发生,整个过程中加了锁。
这个Design的后期他们发现了一个问题,就是vote的那个队列的处理有时非常慢,某些Vote甚至要几个小时之后才能被处理到,这个现象在Traffic很大的时候尤为明显。所以他们首先想到的是可能consumer太少了,需要加多一些consumer来同时处理,然而他们发现加了多个consumer之后好像变得更加糟糕了。在分析了一些log之后发现,原来是之前那个锁的问题,很多时候需要修改同一个list就会出现等待锁的现象,从而影响了性能。
Reddit当时是怎么解决的呢,他们的解决方法就是进行partition,把vote根据子版块的link来进行partition,分发到不同的queue中,从而减少等同一个锁的发生:
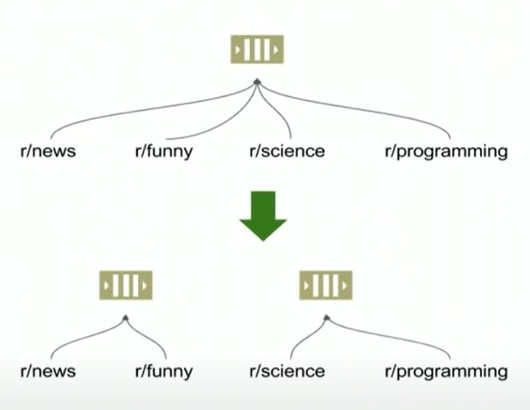
这种修改之后,平均执行时间得到了很大的优化,但是P99并没有很好的改善。主要原因还是因为有一种称为domain的listing仍然会出现等待锁的情况发生,就是我们之前的根据子版块的link来进行partition的时候,它可能还是会属于同一个domain,从而产生争抢同一个锁的现象出现。因此他们对这种情况也做了一个优化,就是把一个点赞进行不同query的处理,也就是分发到不同的队列进行处理,这样就不会相互影响了。
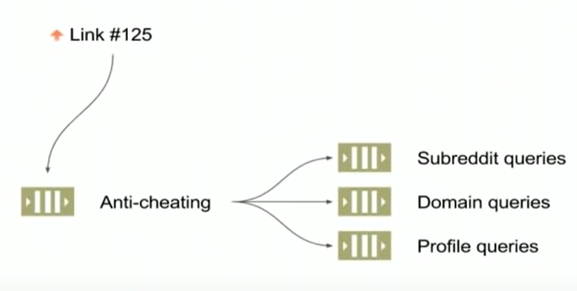
当然这个问题的根源还在于锁的使用,他们内部也在实验一些不使用锁的方案,另外他们也在使用现在看来更加常见的创建这种list的方案,比如引入Machine learning结合offline的分析来产生list,而不是简单根据vote来进行排序。
Things
Thing我们可以认为是储存在PostgreSQL和MemCache中的数据模型(原本也在r2中,只是后来分离出来),基本来说由两种表构成,首先是thing table,它里面的column都是用来为Reddit的sorting以及filter来服务的,如下图所示:

另外一个表就是真正的数据表,也就这些id对应的真正数据,如下图所示:

整个PostgreSQL本身是一个cluster,有自己的primary和replication,主数据库用来服务写,replication可以服务读服务,他们之间是通过async来进行同步的。R2的读写会访问对应的Primary和replication,同时在其上也有一层Cache,所以会先访问cache,如果miss才会去PostgreSQL去进行读,这里不同于我们平常理解的Cache,在向Primary进行写的同时,他们也会同步更新Cache里面的内容。
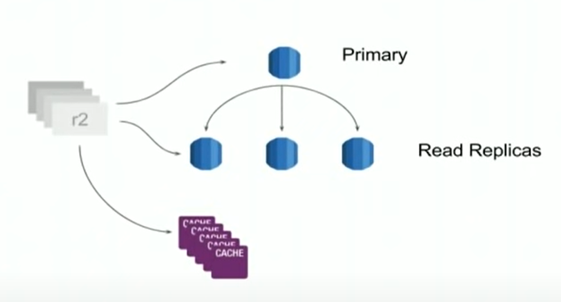
上面提到的这种Cache更新策略听起来还不错,但是这里肯定就会存在一致性的问题,比如说数据库写失败了,但是Cache还被更新了,这样一来就会出现问题,果不其然,他们很快就发现了数据的不一致,比如说这个id在cache中存在,但是想去数据库中查询具体内容的时候根本没有这条数据,这可把他们急坏了,赶紧写了一个tool去定期把cache中和数据库中不一致的数据进行删除(团队人数比较少,先解决痛点再说,哈哈)。
然后他们再进行深入分析,发现了数据库写失败的情况一般发生在Primary的性能出问题尤其是disk IOPS比较高的时候,所以他们团队想了一个办法,把数据库的机器搞一个性能更加强大的机器,这样出现问题的概率就降低了。
然后他们很快又发现有数据不一致的问题了,这次出现问题的原因是Failover,在上面我们提到的primary和replication的架构中,他们有时需要进行primary的切换(比如需要进行机器的维护等),他们的算法很简单,就是从replication中找一个数据库来当primary,但是他们的代码中有一个bug就是在切换primary之后的某一个短的时间内,原有的primary还是可以接收数据的写(他们没有做非primary不能接受写的权限设置,只是在request level根据读写类型进行了分发而已)。所以他们又加入了一些权限的检查,如果不再是primary就不能再接收写请求了。
Comment Tree
所谓Comment Tree其实就是我们通常说的评论区,你既可以评论原来的内容,也可以评论已有的评论,从而形成了一个树一样的结构,如下图所示:
正是因为有了这样的层级关系,所以每次在查询的时候再去创建这个tree效率就会比较低下,因此他们使用的方法是先pre-compute这个tree的层级关系,如下所示,这样就可以很快速地找到所有的comments。

有了这个之后,在插入一条新的comment的时候,(也是通过queue和一个额外的job来进行处理的,可以通过batch操作来进行update以提高性能),就同时需要对这个结构进行处理,这里处理的时候要注意comment的时间顺序,就是在插入子comment的时候要保证父comment已经存在,否则就需要做一些额外的处理,进行re-compute,记住这个re-compute哦,后面马上我们又会提到。
针对一些特别hot的事情发生时,就会有很多comment产生,而且这些comments会发生在很短的时间内,整个处理comment的queue就会被这个事情占满,从而导致别的事件的comment也会收到影响,他们使用了一个称之为Fastlane的技术来让这个hot的事情独享一个queue来单独处理,从而减少对别的comment的影响。
而也是这个Fastlane的技术导致了一个新的Bug,你可以理解Fastlane是针对那些突然hot的thread的comment的,当超过一定阈值被判断为hot的comment就会直接发送到Fastlane的单独的queue进行处理,而原来queue里面的针对这个事情的comment就会被忽略从而不再处理,正是这种设置导致fastlane那边的message进行处理的时候发现了数据不一致(比如找不到父comment,因为它还在原来的comment queue里面,被忽略了),于是它就要求进行re-compute(你可以理解重新从数据库中读取数据进行修复),而这个re-compute是非常耗费资源的,当re-compute一直发生的时候就会出现memory不够的问题,也正是这种memory的持续消耗导致整个系统最终都出现了问题。另外为了防止这种一个queue消耗过多资源的事情再次发生,他们还增加了一个queue Quotas的限制来限制一个queue的长度从而限制它能使用的资源数量。
AutoScaler
这个比较好理解,就是整个网站的使用其实是有波峰和波谷的,如下图所示:
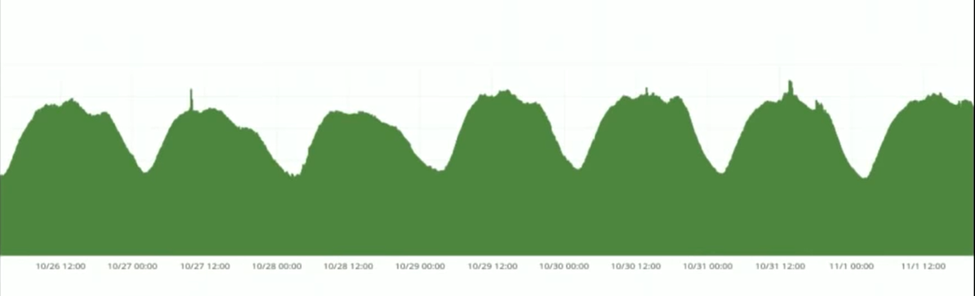
AutoScaler的主要作用就是在波谷的时候我们可以少启动几个instance,在波峰的时候再多启动几个instance,甚至有更大的峰值出现的时候,也能够自动scale更多的instance。这个波峰和波谷是通过load balance的使用率来进行判断的,然后trigger AWS的auto scale就可以了,总体来说思路比较清晰。另外AutoScaler还需要知道当前各个node的健康状况来决定是否要增加和减少node,它的做法是让每个node都register到一个Zookeeper中,这样就可以通过心跳机制来探测node的健康状况了。
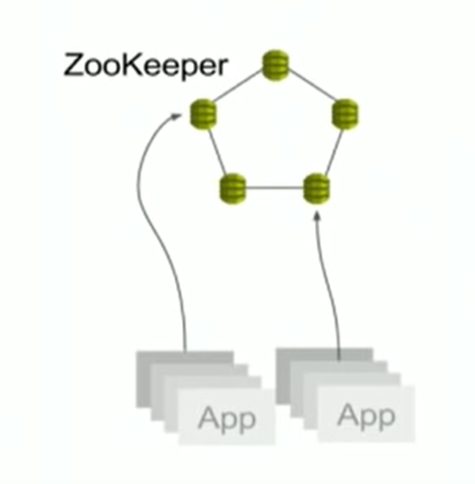
这个架构也导致了一个新的问题,就是他们在16年的时候从EC2 classic migrate到VPC,这个ZooKeeper的migiration尤其重要,所以比较理想的migrate顺序是这样的:
- 在VPC上启动新的的ZooKeeper.
- 停了autoscaler服务。
- 把所有的server上的注册信息指向新的ZooKeeper。
- 把autoscaler的服务使用新的ZooKeeper cluster.
- 启动autoscaler服务。
- 整个过程完成,用户完全没有感知。
而真的开始migrate的时候,事情没有想象中这么好,在第一第二步的时候都很好,创建了新的ZooKeeper,停止了autoscaler服务。但是在执行第三步的时候,当有大概1/3的server注册到Zookeeper的时候,整个系统突然出现了问题,原因很简单,当时为了防止autoscaler服务因为某些异常停止,有一个auto restart这个service的功能,在我们第二步停止了autoscaler服务的之后,这个服务又被重启了,这样一来,凡是在第三步被重指向新的zookeeper的server都被认为出现了问题(因为被自动重启的autoscaler还是指向旧的zookeeper)。知道原因之后进行解决就简单多了,他们后期也开始尝试使用service discovery来进行判断节点是否healthy,也算是一个改进。
总结
个人觉得整个Reddit的架构演进过程中真的遇到很多现实的问题,很开心也很感谢他们把这些经验分享出来了,希望也能对您的工作有所帮助。



Recent Comments