一文带你深入理解Serializable隔离最新技术SSI
我们已经在前文了解了数据库的弱隔离以及Serializable隔离的两种技术(串行执行和两阶段锁),每个人都想用Serializable隔离,毕竟它很好的处理了各种冲突。但很多时候又被逼无奈选择弱隔离,原因也很简单,Serializable隔离好虽然好,但是性能消耗太大了,选择它就意味着选择了低的性能。所以人们一直在感叹假如有一种方法能做到Serializable隔离,性能损耗又不大的话就好了。皇天终归不负有心人,一个新的算法横空出世,它就是Serializable Snapshot isolation,简称SSI,它的优点就是能够牺牲很小的性能达到Serializable隔离的效果,这个算法是2008才出现的,不过已经被运用在PostgreSQL的版本9.1和FoundationDB中了。本文就来详细介绍一下这一最新的技术。
悲观和乐观的同步控制
我们在《Transaction Serializable隔离之两阶段锁》中提到的两阶段锁其实就是一个悲观的同步控制策略:任何有可能出现冲突的数据,我们都加锁(不管是不是真的会有冲突),就有点类似多线程的编程。而《Transaction Serializable隔离之串行执行》中提到的串行执行,更是把悲观做到了极致,直接变成串行的单线程编程了。
相比较上面两者来说,SSI则是一种乐观的同步控制:假设所有的同步都是不产生冲突的,每个Transaction都能够互不干扰地执行,只在提交之前进行检查,假如发现了冲突,阻止提交进行重试。只有符合serializable的transaction才能够提交。
其实使用悲观还是乐观的同步控制大家争论了很久,他们在不同的场景下各有其优缺点,比如说乐观的同步控制在一个经常发生冲突的系统中就会带来很糟糕的体验,毕竟你的假设不符合系统的实际情况,这样一来就会有很多重试的处理,从而加大系统的资源消耗,在一些系统资源本就很紧张(接近极限)的情况下反而不如悲观的同步控制,反之亦然。
既然乐观同步控制不是什么新鲜的概念,SSI又有什么优势呢,正如它名字所说的,它是基于Snapshot隔离的,也就是说所有的读是从一个一致的snapshot来获取的。这就和早期别的乐观控制不同,SSI正是基于此来开发了一个算法探测Serialization的冲突从而决定哪个Transaction去abort的。
基于过时假设的决定
我们在之前的《Transaction弱隔离之Write Skew和Phantoms》中讨论过Write Skew,它的流程是一个transaction从数据库中读一些数据,检测相关的结果,然后基于结果决定做一些操作。这里的问题就是在snapshot隔离中,我们读的结果可能已经过时了,也就是说被别的transaction更新了。所以我们之前的基于结果决定做的操作可能不是我们想要的。
当我们读数据的时候,其实数据库并不知道应用程序怎么使用这些数据(你可能只是显示,也可能基于读的结果做某些操作),所以为了安全,数据库一般会说假如有任何transaction改变了你查询的结果就是不valid的。所以为了提供Serializable的隔离,数据库需要能够探测到这种情况,一般怎么做呢?有两种方法:
- 探测所有基于Stale MVCC object 版本的读(没有提交的写发生在这个读之前)
- 探测所有影响之前读的写操作(写发生在读之后)
探测Stale MVCC读
还记得我们在《Snapshot的隔离和Repeatable的读》中提到的多版本控制吗?也就是说当一个transaction读的时候,它会忽略也没有提交的写。依然来看我们之前提到的医生值班的例子,Transaction 43开始读的时候,Transaction 42还没有提交,所以它读的时候Alice的on_call还是为true。但是在43提交的时候,42已经提交了,这就意味着提交时候其实42的修改已经生效了,也就是说43看到的内容其实已经是不对的了,这个时候就需要abort 43的操作。
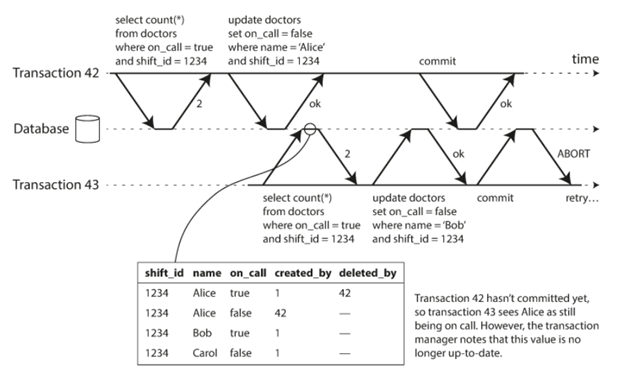
实现也就很简单了,就是在提交之前会检查一下是否有任何写操作提交了,假如有了就需要abort。为什么我们等到提交的时候才检查呢?原因也很简单,因为我们其实并不知道42会对查询到的数据做什么操作,假如只是简单地读,我们完全没有必要去abort 43。这样一来我们就不会出现没有必要的abort操作了。
探测所有影响之前读的写
另外一种情况就是一个transaction修改了之前读的数据。如下图所示:

我们在之前《Transaction Serializable隔离之两阶段锁》中有提到索引区间锁的概念,这里其实使用了类似的技术,如上图所示,Transaction 42和transaction 43同时查询了Shift1234的值班医生,假如我们对Shift_id加一个索引,数据库就可以使用entry1234来记录transaction 42和43正在读这个数据(这个数据只要保存一会,当transaction结束时就可以丢掉了)。这样一来当有transaction想要写这个数据的时候,它需要取index那边看看是否有transaction正在读这个数据,这和锁有点类似,但是不是block,而是说当有问题的时候,通知那些读操作:你们之前读的内容被修改了。
在上图中,42的更新就会去查看想要的索引表,然后知道42也同时读了相应的数据,这样就会通知42去abort。
SSI的性能
和两阶段锁相比,SSI最大的优点就是它不需要等待另外一个transaction的锁。就和snapshot隔离类似,写不会block读,读也不block写。尤其是只读的transaction不需要请求任何锁,性能得到了很大的提升。
和串行执行相比,SSI的性能不再局限于单CPU,我们可以利用所有可以利用的资源来提升性能。
当然SSI的性能很大程度受abort的概率的影响,比如一个长时间的读或者写就会有很大概率被abort,所以一般来说SSI还是希望读写的transaction比较短。
总结
本文我们详细介绍了Serializable隔离的三种实现,他们各有其利弊,希望通过这些文章介绍,你能够对Serializable隔离的实现有个大概的了解。



Recent Comments