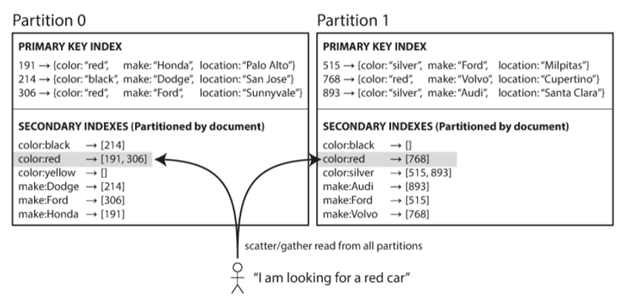
我们在之前的文章中讨论了replication的各种实现,我们都知道replication就是把同样的数据在不同的节点上保存副本。这里有一个问题,就是当数据很大的时候,我们需要把数据分成不同的部分进行保存,这个过程就称之为partition,有时也称之为sharding。 通常来说我们需要进行partition的目的并不是说磁盘的空间不够,而是更多地为了scalability,就是说当数据大了之后,query的量过大后,很多时候磁盘的IO等就会成为一个瓶颈,我们就可以把数据分散到不同的磁盘或者不同的节点上,这样就可以分散query的压力,从而提高性能。 Partition和Replication Partition之后是否就意味着每个磁盘上存储的数据就变小了呢?其实不然,很多时候我们会和replication结合起来,让剩余的磁盘保存别的partition的拷贝,通常情况下会让active的partition分散在不同磁盘或节点上,从而达到balance的目的。 举个leader-follower的例子,它在磁盘和节点上的存储可能如下图所示,理想状况下,我们希望每个节点只有一个leader,其余的是follower(当然出问题的时候,可能就会有多个leader)。...

Recent Comments