关系型数据库进阶之Log Manager
我们在之前的文章中聊到,数据库为了提高它的性能,会把数据存在memory buffer中。但是这里有一个问题,就是假如一个已经committed的transaction crash掉了,你因为这个crash丢掉了memory中的数据,那就会出现了Durability的问题。当然你也可以把所有的数据都写到磁盘中,但是同样的问题,假如写到一半就crash了,这里就会发生原子性的问题。
所以这里我们的原则是任何通过transaction进行写的修改要么是全部完成要么就是什么都不做。
为了解决这个问题,有两个方法:
- Shadow copies/pages: 每一个transaction都创建它自己的数据库(或者部分数据库)备份,然后在这个备份上进行操作。假如有错误,这个备份就移除掉。假如成功了,就切换到这个备份上,而把旧的备份删除掉。
- Transaction log:transaction log是一个存储空间。在把数据写到磁盘之前,数据库把相关的信息写到transaction info中,因此即使有crash或者cancel的时候,数据库也知道怎么来完成或者移除响应的没有完成的transaction。
WAL
Shadow copies/pages的思想其实很好,唯一的问题就是在大的数据库中,会额外浪费很多磁盘的空间。这也是为什么现在主流的数据库都是用transaction log来解决这个问题。Transaction log必须存储在一个稳定的存储空间中。
大多数数据库(至少Oracle, SQL Server,DB2, PostgreSQL, MySQL以及SQLite)都使用Write-Ahead Logging protocol (WAL)来处理transaction log。这个protocol主要有三个规则:
- 每一个对数据库的修改都产生一个log记录,并且log记录必须在数据写到磁盘前写到transaction log中。
- log记录必须按照顺序写,也就是说记录A先发生,那么记录A就必须先写。
- 当一个transaction committed了,这个commit的顺序必须在transaction结束前写到transaction log中

这些工作都是在log manager中处理的,他位于cache manager和data access manager之间,比如每一个更新,删除,创建,commit,rollback都需要写到transaction log中。听起来很简单,对吧?这里最大的问题就是性能问题,总的说就是假如transaction log很慢,那么它就会让所有的东西都慢起来。
ARIES
1992年,IBM开发了一个加强版本的WAL,我们称之为ARIES。现在ARIES总归多多少少在现代数据库中被使用。关于ARIES,推荐大家去读读这个论文。这里就是简单概括一下:
ARIES就是Algorithms for Recovery and Isolation Exploiting Semantics。这个技术就两个目的:
- 当写log的时候有很好的性能。
- 有一个快的和可靠的恢复。
有很多原因数据库都会rollback一个transaction:
- 用户取消了它
- 有server或者网络错误
- 因为transaction破坏了数据库的完整性(比如数据中有一个UNIQUE的列,然后这个transaction加入了一个重复的列)
- 因为死锁
有时候,数据库需要能恢复transaction(比如有网络的错误等),那怎样实现这个恢复呢?在回答这个问题之前,我们先来看看有哪些信息被存储在log记录中。
Logs
每一个transaction过程中的操作(add/remove/modify)都会产生一个log,这个log的记录由下面这些部分组成:
- LSN: 这是一个唯一的Log Sequence Number。LSN是按照时间顺序来记录的*,这也就意味着假如操作A在操作B前面发生,那么log A的LSN比log B的LSN要小。
- TransID:产生这个操作的transaction的id。
- PageID: 修改数据所在的磁盘的位置。
- PrevLSN:指向同一个transaction中的上一个log记录。
- UNDO:去除这个操作影响的方式。比如假如一个操作是更新,那UNDO就会保存更新值之前的value/state,这样就可以很方便地做UNDO的操作。
- REDO:重放这个操作的方式。这里有两个方式来做这件事。要不你保存操作之后的value/state,要不你保存这个操作本身,这样就可以重放。
- 。。
为了给你一个更好的理解,我们来看一个简单的例子:UPDATE FROM PERSON SET AGE = 18;我们假设这个查询是在transaction 18中执行的。

每一个log都有一个独立的LSN。这些log在同一个transaction是连接在一起的。这个log是更加时间顺序来进行连接的。
Log Buffer
为了防止log的写入成为瓶颈,这里会使用log buffer。
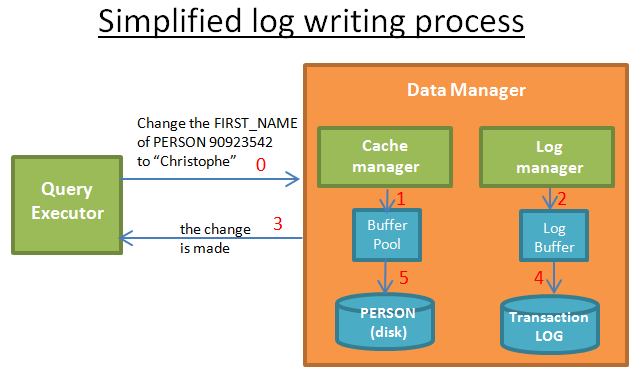
当query执行器请求一个修改的时候:
1)这个cache manager保存相应的修改到一个buffer中
2)log manager保存相应的log到它的buffer中
3)这一步,query执行器会认为这个操作完成了(也意味会有别的修改)
4)log manager会把相关的log写到transaction log中。什么时候写是由算法决定的。
5)cache manager把相关的修改写到磁盘中。什么时候把数据写到磁盘中也是由算法决定的。
当transaction commit的时候,也就意味着步骤1,2,3,4,5都已经完成了。写数据到transaction log是非常快的,因为它只是“加一个log到transaction log中某一个地方”,而把数据写到磁盘则是更加复杂的一件事。
STEAL和FORCE策略
为了性能,有时候上面的步骤5会在commit之后才完成。因为即使这时候发生crash,也能够通过REDO logs来回复。我称之为NO-FORCE策略。
当然数据库也可以选择FORCE策略(步骤5必须在commit之前完成)来降低恢复的负载。
另外一个问题是数据是否一步一步写到磁盘中(STEAL策略)或者buffer manager是否需要等待commit顺序来把所有的数据一次性写到如(NO-STEAL)。究竟是选择STEAL还是NO-STEAL取决于你想要什么:更快的写入,但是恢复很慢还是更快的恢复?
下面是这些选择的影响:
- STEAL/NO-FORCE需要UNDO和REDO:性能最好,但是提高了log的复杂度以及恢复的流程。如何选择取决于具体的数据库。
- STEAL/FORCE只需要UNDO
- NO-STEAL/NO-FORCE仅仅需要REDO
- NO-STEAL/FORCE什么都不需要:但是性能也是最差的,而且需要最大的ram
恢复的部分
现在我们有了log,让我们来看看如何来使用它。
假设现在数据库crash了,我们重启了数据库,并且开始进行恢复的流程:
ARIES根据三个pass中从crash中恢复:
- 分析pass:恢复的流程从所有的transaction log中读取整个时间性,并且看看在crash发生的时候究竟发生了什么。这也决定了哪一个transaction来进行rollback,并且哪些数据需要在crash的时候写到磁盘中。
- Redo pass:这个pass就是根据上面分析pass中得到的log记录来使用REDO更新数据库的状态。在REDO的过程,REDO的log是根据时间顺序来执行的。
对每一个log,恢复的过程先读取page中的LSN:假如 LSN(page_on_disk)>=LSN(log_record),这就意味着数据已经在crash之前写入到了磁盘中。所以不需要做什么。假如LSN(page_on_disk) < LSN(log_record),则需要更新磁盘中的相应page。
- Undo pass:这个pass会roll back所有在crash之前没有完成的transaction。rollback从每一个transaction的最后的log开始,按照逆时间的顺序执行UNDO log。
这里分析phase的目的就是使用transaction log来发现crash发生之前发生了什么。为了加速这个过程,ARIES提供了一种称之为checkpoint的概念。总得思想就是把transaction表和dirty page表以及最新的LSN不时写入磁盘中,所以在分析pass过程中,只要分析LSN后面的log就可以了。
至此,我们就完成所有关系型数据库进阶分析,这些内容真的很多,但很开心我们终于写完了,希望大家能够喜欢。




Recent Comments