深入浅出理解数据的序列化和反序列化
一般来说,数据的处理有两种类型。一种是在内存中,比如我们常见的结构体,list,数组等等。而另外一种就是把数据写到文件中或者在网络中进行传输,这个时候的数据传输说白了就是比特流,那么接受方如何解析这些接收到的比特流呢?这个时候就需要对数据进行序列化,把相应的数据转化成可以自解释比特流。然后接收方就可以通过反序列化的方法把这些比特流再转化成相应的结构体等等类型。
各种语言自带的格式
很多语言都有自带的序列化方法,比如Java.io.Serializable,Python的pickle等等。它们用起来很方便,但是也存在一定的局限性:
- 假如序列化是来自于特定的语言,那么反序列化也得是相应的语言。这就给不同语言之间的交流(比如客户端和服务端使用不同语言)带来了困难。
- 因为允许反序列化时实例化任意的类,所以很容易造成漏洞,给安全攻击带来了可能。
- 这些语言特定库的向前和向后兼容性一般都不太好。
- 性能一般来说都不是很好,它们的CPU使用率以及压缩比一般来说都不是很理想。
所以一般来说不太会使用语言自带的序列化和反序列化函数,那么除了语言自带的函数还有哪些选择呢?
JSON,XML和CSV
比较常见的不依赖于语言的序列化标准有JSON, XML。前者因为其是浏览器的内置支持格式而流行,后者则有时被大家认为太繁琐和复杂了。当然还有CSV格式也有很多人使用。这些格式其实对人的可读性来说都比较友好,但也各有其问题:
- 数字的序列化比较差。XML和CSV你基本上很难区分数字和包含数字的字符(除非特殊处理)。JSON虽然好一点,但是它不能区分整数和浮点数。
- JSON和XML支持Unicode的字符串,但是不支持binary的字符串。虽然有一些方法来解决这个问题,但是也需要付出相应的代价。
- CSV不支持schema,所以都是应用程序自己来决定每行和每列的内容。
除了这些问题外,其实JSON, XML和CSV都还是不错的,目前也还算比较流行。
二进制编码
JSON和XML还是不错的,但是他们的数据有时还是有点冗余,在小量级的数据下这个问题并不是很明显,但是当数据大了之后,这个问题就显得尤为突出。所以在此基础上就出现了很多二进制编码的技术,比如基于JSON的MeessagePack,BSON,BJSON,UBJSON等等,以及基于XML的WBXML等。
我们来以MessagePack为例来看一下如何处理下面这个JSON文档。

- 第一个byte是0x83,这里前面的4bit 0x80表示这个是一个object,后面的4bit 0x03表示这个里面有3个域。
- 第二个byte是0xa8,其中前4bit 0xa0是说这个是一个string,长度是由后4bit决定的0x08,也就是8byte的长度。
- 后面的8个byte就是userName的ASCII编码。
- 后面的0xa6和之前的0xa8是类似,只是长度这次变成6.
经过这样的编码之后长度就由原来的81byte缩小成了66byte,有大小的好处,但是也牺牲了可读性,究竟值不值得,其实还是仁者见仁,智者见智的事情。这里我们犹豫是否值得的一个重要原因就是其实大小缩小得并不是很明显,下面我们会介绍几种大小减少更明显的方法。

Thrift和Protocol Buffers
Thrift和Protocol Buffers和上面的中心思想是类似的,但是他们各自尤其优点。其中Thrift
是由Facebook发明的,而Protocol Buffers(protobuf)是由Google开发的。
我们首先来看看Thrift,它首先需要定义一个Schema如下:
Thrift有两种二进制编码的格式,一个是BinaryProtocol一个是CompactProtocol。我们首先来看看BinaryProtocol会如何序列化上面的例子:

这里我们可以看到他的第一个byte是类型,主要用来表示是string还是int还是list等等。和上面不同的是这里不再写key的字符串了,比如上面的userName,favoriteNumber等等,取而代之的是一个field tag的东西,这个会设置成1,2,3和上面的schema中key字符串前面的数字,也就是用这里来取代了具体的key值,从而减小的总体的大小。这样的格式压缩之后就只有59byte了。
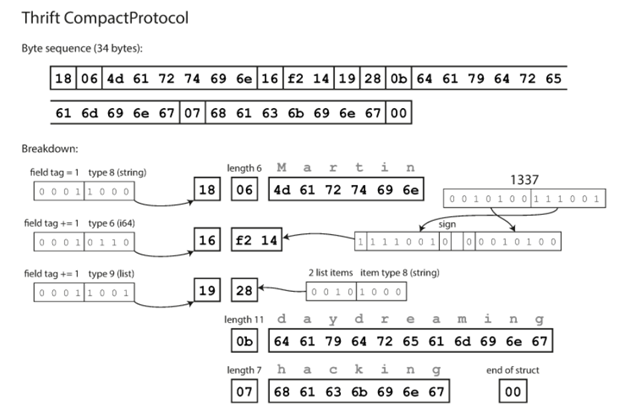
另外一种编码的格式是Thrift CompactProtocl,同样的例子它的结果如下所示,它的压缩比就更好了,同样的内容只要34byte。和上面的差别首先是他把field tag和type放到了一个byte里面。然后length所占的大小根据前面类型不同所占用的字节也不相同,然后像数字1337它不再是用8个byte来保存,而是只用了2个byte,每个byte的第一个bit表示后面是否还有,所以-64到63就只要一个byte,-8192到8191就只要两个byte即可。
看了Thrift之后,我们再来看看protobuf。首先它的定义schema也比较类似:

它的二进制编码如下,和CompactProtocol比较类似,它的大小是33 byte。值得一提的是上面的schema中我们 设置了一个required,这个在编码中其实是没有什么差别的,唯一的差别在于在运行时我们会对这个required进行检查,没有就会出错。这个在向前向后兼容的不同版本中需要特别注意,一不小心就会出问题。

Avro
Apache Avro是另外一个二进制编码的格式,它和Protocol buffers以及Thrift稍有不同。Avro的schema有两种语言,一种就是易读性比较好,另外一种对机器来说比较友好:


我们可以看到这种schema中并没有任何tag的值在里面,而事实上它的比特流中也没有相关的信息,如下所示,只有长度,没有各个tag。

没有这些信息,在读的那一端如何解析呢,其实它有一个要求,就是在读端的schema要和写那边的schema一模一样,这样就不需要传递信息了。还有一种处理方法就是在读端知道写端的schema,尤其是大量传输同样schema的数据时候,我们可以把读端的schema写在最开始的地方,然后就不需要重复传递了。或者我们维护一个不同version schema的列表,这样就可以进行简单查询了。
总结
本文讨论了各种序列化的二进制编码方式,重点介绍了Thrift,protobuf以及Avro,希望能让大家对这个方面有个初步的了解。




Recent Comments