
数据库应用之数据分析
在早期数据库发明的时候主要是用来为实现商业功能的,比如说保存订单的信息,支付员工的工资等等。这类需求更多地是面向功能的,它的要求是相关的请求能够快速及时正确的执行,我们称这个流程为联机事务处理(OLTP, Online Transaction Processing)。 而随着数据库发展至今,一个更加常见的应用场景就是数据分析。比如说如何从淘宝订单中分析出商家每个月的销售情况,如何分析出哪些商品是爆款,如何得到某个新的功能给公司带来的点击量的增加等等。我们通常称这个流程为联机分析处理(OLAP,...
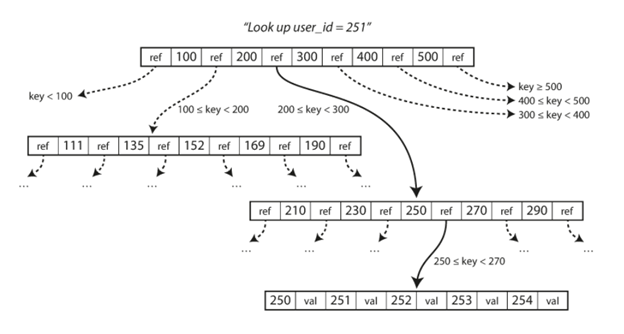




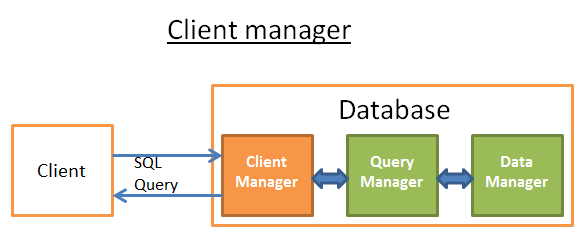


Recent Comments