
Github中的Javascript学习资源推荐
Github上有很多关于Javascript的学习资源,这些资源有教程,有博客,有源码等等。下面就简单介绍一些我看过的Github上的项目: JavaScript Algorithms and Data...
东哥和系统设计开荒小分队的基地
Github上有很多关于Javascript的学习资源,这些资源有教程,有博客,有源码等等。下面就简单介绍一些我看过的Github上的项目: JavaScript Algorithms and Data...
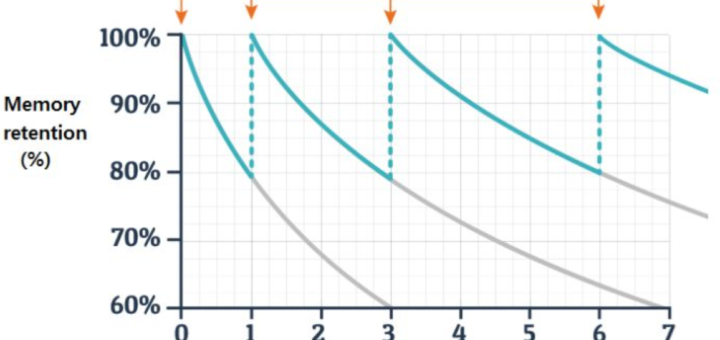
我们通常会发现很难记住我们曾经读过的东西,就像上图所示,随着时间的推移,所读的东西会渐渐忘记,只有不断的复习,才能够真正地把它们记住。有时,我也想不停地去复习他们,但是总是会忘记这件事,要是能有一个系统不断地提醒我做这件事就好了。我想我所遇到的这个问题,应该也是大家平常会遇到的。 其实市面上,也有一些网站可以实现这个功能,比如readwise.io,它就会每天给你发送提醒的邮件。那么我就在想,我们能不能自己也做 一个呢?想到就做吧,正好最近也在学习Python,那就让我们一起来试试看能不能实现这个功能。 首先来看看我们要实现的功能: 从你的数据集中找到笔记和突出显示的内容...
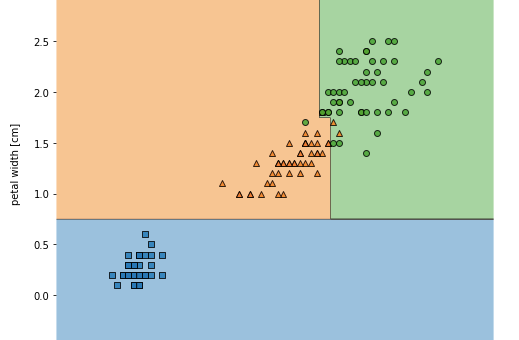
本文将会介绍如何用Python实现一个决策树分类器。主要包含下面两个方面: 什么是决策树? 使用Python实现决策树 什么是决策树 简单来说,决策树算法把数据按照树的结构分成了一系列决策节点。每一个决策节点都是一个问题,然后可以根据这个问题把数据分成两个或多个子节点。这个数一直往下创建,知道最终所有的数据都属于一个类。创建一个最佳决策的标准就是信息增益。下图就是一个简单的决策树示意图:...
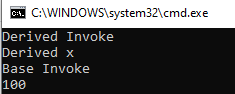
今天我们和大家介绍一下C#中的new修饰符,注意这个修饰符,不是我们创建class的new哦。 new修饰符的基本介绍 New 修饰符主要要在子类中,当他修饰一个方法或者成员时,就表示,我们在基类中也有同样名字的方法或者成员,这里我们相当于重新建了一个同名的方法或者成员。在调用的时候,也就会覆盖基类的调用。当然我们不加new这个修饰符,也是可以运行得,但是会在编译的时候报警告。我们来来看下面的代码: 这里,我们在基类中也有一个和父类同名的Invoke函数,假如我们这样写,在编译的时候就会出现下面这样的警告:...
软件工程的KPI是一个很重要的指标,它可以用来衡量软件团队的performance。因此,他需要比较稳定,并且能够覆盖没一个人所做的工作,最重要的是,可测量的。 因为他是用来展示整个团队的工作的,所以选择正确的metrics来测量很关键,否则就没有用了。 一些我所常见到的错误就是看提交了多少行代码,有多少个commits,甚至deploy了多少次等等。当然,不是所看deploy多少次是有错的,主要还是看你想要观察的是什么(有可能和生产率没有关系) 通常,很多关于KPI的文章都关注了很多metrics,但是很少在现实中能够使用。因此,这篇文章中,我将会选择5个工程师KPI metrics,如下面所示,供大家参考。...
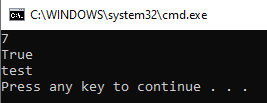
众所周知,在C#中所有的class和struct都会继承object类。所以,在C#中,每一个object都有一个ToString的方法,他会返回相关的string。比如我们来看一下下面这个例子: 他们的输出如下: 下面我们来看一个类,这个是一个很简单的类,他包含两个property name和Age,这里我们就overrid了ToString的函数,你可以使用任何你想要的方式来重写这个函数,只要return一个string就可以了。 调用的代码如下:...
自从手机有了摄像头之后,我们可以很方便地把生活中的瞬间记录下来。我们可以通过照片和视频来回顾那些美好的瞬间。自然而然,和我们最爱的朋友和家人分享这些照片和视频就成为了一个必然的需求。 所以,在你写一个app的时候,很可能就希望他能支持拍照和拍视频的功能。假如你还不太清楚怎么来实现的,本文就是来简单介绍如何使用React Native实现相关的功能。 预先安装的包: expo-camera:这个包是用来拍照和视频的。...
DeepMind其实包含两个方面:Google AI业务背后的创新以及其相关的组织。DeepMind是Alphabet(Google母公司)的辅助机构。 DeepMind已经集成到Google的各种工具和产品之中了,当你使用Google Home或者Goolge Assistant的时候,DeepMind无处不在。...
将经验丰富的企业家和新手区分的重要标准之一就是愿意和承受风险的能力。你可以从世界上最好的企业家身上看到这一点,包括Richard Branson,Arianna Huffington以及我们的马爸爸。 不管你的公司是什么类型和规模,小的公司也好,大的全球性的企业也罢,都有可能犯一些共同的财务方面的错误。 企业家们都很聪明,他们能够快速地解决问题,找到他们的领域的界限并突破他。他们总是在寻找每一个机会来发现自身的短板,并且在未知的领域奋斗。企业家愿意承担风险的趋势随着他们把风险和机遇结合能力的增加而增长。...
无论你是从Node.js还是浏览器调用一个API Call,连接失败总是会发生。有些request的失败是调用相关的错误,比如客户端发送了一个错误的数据。另外一些则是连接的问题,比如连接到服务器的问题,或者是这之间的某一个节点出现了问题。虽然API和web服务检测可以看到这些问题,但是一个更好的方案也许可以处理这个问题。 解决这个问题,你可以在你的HTPP调用中加入一个重试的机制。这可以让你的API调用成功。有些库,比如got,就支持失败的重试,而另外一些库,比如axios,则需要一个独立的插件。但是假如你的库不支持这个,那么可以参考这篇文章。我们将基于返回的status来决定如何重试一个请求。 重试的基础 决定何时需要重试一个request,我们需要知道正在找寻什么。有很多HTTP...
Follow:

More




Recent Comments